PRO 23 is a unique project for a number of reasons, none less so than it is our first ever volunteer digitisation project at The National Archives. That means that not only are the volunteers generating the catalogue data, but they are also generating the digital surrogate images of the seal moulds that appear on Discovery, our catalogue, as well!
The project leader, Amy Sampson, has written a lovely blog post about the project from inception to being live on Discovery, and has asked that I discuss how we worked together to ensure the surrogate images and metadata meet The National Archives’ required digital preservation standards. In other words, to explain how each image would need to be captured to a certain standard, be in a specified format, have accompanying descriptive and administrative metadata, and be able to conform to our standards for ingest into our Digital Records Infrastructure.

A volunteer creating a PRO 23 image and associated metadata
The nuts and bolts
Image capture standards: We have requirements around the required image resolution, image format and other technical aspects of the image capture. These ensure we are getting the best quality image that loses none of the detail of the original object. The format allows us to compress the image so it requires less storage space, but again without the loss of any information.
Descriptive and administrative metadata: Metadata is data that describes other data. ‘Descriptive metadata’ is the information you see on Discovery, in this case information such as the original seal owner, the colour of the original seal and the physical format of the seal mould all count as descriptive metadata about the original seal and the seal mould itself. ‘Administrative metadata’ is technical information about the image that we capture and preserve alongside the images. Information such as the image format, the image resolution and a checksum[ref]A checksum is a unique ‘fingerprint’ for each file, made up of letters and numbers. No two checksums will be the same unless the content and format of a file are identical. You can generate new checksums for a file and check it against the original checksum, to ensure that the content of the file has not changed.[/ref] for the image would fall under administrative metadata. Both types of metadata are important, as the descriptive metadata allows us to provide as much information as possible to the end user and administrative metadata ensures we know what we have inside our Digital Archive and can manage it effectively over time.
Ingest into our Digital Records Infrastructure: Ingest is the word used to encompass the action of copying into our Digital Archive and validating over the data provided, to ensure it meets our required standards as discussed above. Anything that does not meet the standards would fail ingest, so it is important to get it right. Digital Records Infrastructure is the name we give to the modular and extensible set of networked systems that underpin and drive the Digital Archive of The National Archives. We call it DRI for short!
Mission not impossible
Once Amy had described the aims of the project to me, I got to work determining how to best facilitate this project so that the volunteers would feel empowered to carry out a number of tasks in order to meet the requirements described above, while not making it so complex that no one would want to take it on! One of the volunteers has written a great blog post on this very project so you can read about it from their point of view.
It was very important that I did not create a solution in isolation, but that Amy and I had frequent conversations about the project and that I understood her vision and what success would look like. Not only did we have to meet digital preservation standards, but we also had to ensure that the descriptive metadata that would appear on Discovery would meet cataloguing standards, and so a core part of this process was also working closely with the cataloguing team.
In the end the solution we arrived at was that the volunteers would capture all the required descriptive metadata and output the surrogate images to our required image standards, but in TIFF image format rather than in our required JPEG 2000 image format. I created documentation for the project, so that the volunteers and Amy could have something to refer to as needed around the metadata and image requirements.

Scanned moulds from PRO 23/679 (E 326/10672)
Once a set of images and accompanying metadata is completed it is passed over to me. I carry out the conversion of the images to JPEG 2000 image format using a piece of in house software, which also generates the required administrative metadata. I wrote a small Python script[ref]Python is a computer programming language. In this instance, a Python script was written to utilise Python to amalgamate information from the administrative and technical metadata files to meet the requirements for ingest into DRI. This Python script removes the need to manually copy and paste data from the administrative and descriptive metadata files.[/ref] to then generate the final descriptive metadata required – this amalgamates some of the administrative metadata with the descriptive metadata and ensures the relationship between the image and its description is maintained.
I then ingest it into the DRI. Once in the DRI I can export it across to Discovery, from where the descriptive metadata and surrogate images are available for free to the public. Following this approach ensures that the images and their accompanying metadata are preserved as well as accessible. It’s a very satisfying project to work on and really demonstrates the value of cross-departmental working and supporting volunteers to achieve amazing things!
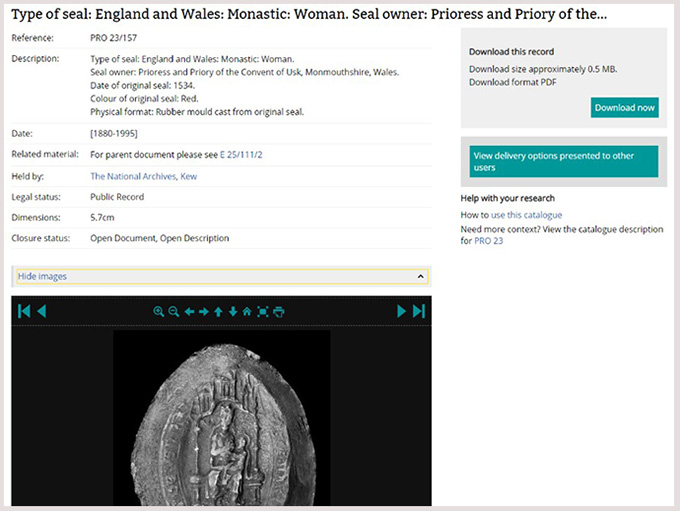
A typical PRO entry in Discovery