Our Research Exchange series features the work of researchers across The National Archives in which they discuss their new discoveries and their work’s potential for impact. The purpose of the series is to highlight and demystify the research we do and open it up to new ideas and discussion.
This month and next, to coincide with our upcoming Annual Digital Lecture, we will be publishing a series of blogs focusing on different aspects of digital research happening at The National Archives.
Our staff will be writing and reflecting on their research, discussing topics such as using AI in archives, using 3D Virtual Tech to access heritage collections, archiving citizen research projects, and much more.
John writes …
The National Archives has benefitted from the generous work of volunteers for years, welcoming community engagement with our collections as we become the inclusive archive.
This engagement with communities who donate their time and expertise to research projects can take place in person or online. We are beginning to see new ways to engage with audiences using immersive technology such as 3D virtual reality spaces that are providing access to cultural heritage collections. These technologies try to embody the physical world by placing objects on display in virtual galleries accessible to the public through either standard web browsers or more immersive VR headset technologies.
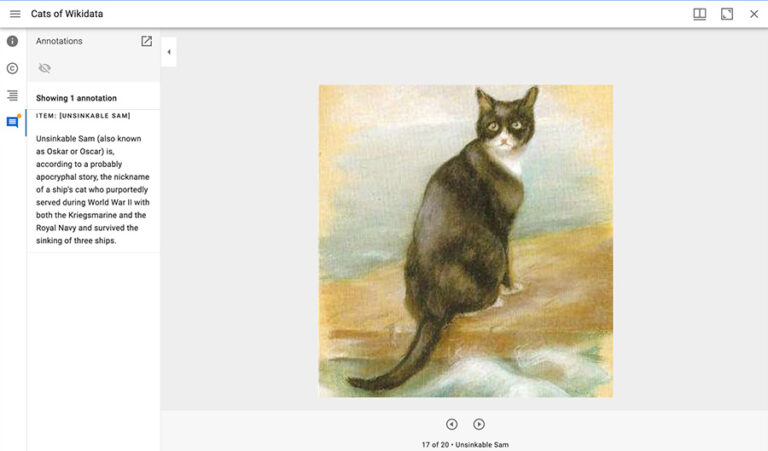
Mozilla Hubs is an example of an open-source project providing the infrastructure possible to build these immersive experiences. Figure 1 shows an example gallery in Mozilla Hubs using images of cats available via Wikidata.

Although these technologies provide engaging ways for users to interact with one another and the content on display, they present challenges when it comes to facilitating contributions from the public. This problem is handled by projects such as Wikipedia or Zooniverse through a review process driven by community editors or volunteers. This approach requires significant investment in both technical infrastructure and community expertise but has demonstrated success at scale.
Historically, citizen science projects such as SETI@Home adopted a more distributed model that offloaded the computational burden of the work. Each volunteer offered access to CPU time on their personal computers to contribute towards a single goal, which in the case of SETI@Home was the search for extra-terrestrial intelligence. Open-source software projects have also adopted a more distributed approach to the way they manage access and changes to source code, which has been popularised by technologies such as Git running on social coding platforms such as GitHub. This approach typically involves taking a copy of the project and making changes to a local copy offline. Changes are submitted back to the original project through a review process which allows the project maintainers to decide whether to accept them.
What if we apply this traditional open-source model used for software development to allow the community to annotate our collections? This would give volunteers more latitude to respond to the data, inviting unexpected and unplanned-for responses to the collections, and would support the data integrity and quality assurance workflows that would enable re-use of the data without requiring complex centralised infrastructure.
To help explore this we are developing a chatbot called ‘Miiifybot’ that allows the community to contribute its knowledge to the collections on display within a virtual gallery in Mozilla Hubs. All contributions go through a review process facilitated via GitHub before being accessible within the platform or within standard IIIF viewers such as Mirador (as shown in figure 2). By using standards for annotating data, we can display the community contributions made within the chatbot directly within IIIF viewers.
Miiifybot is designed to run within the messaging platform Discord which in turn is integrated into the chat system of Mozilla Hubs. A key part of its infrastructure comes from the web annotation server Miiify which is built using a distributed database technology following the same principles as Git.
We have described the technology behind a chatbot designed to support annotating items on display within a 3D virtual gallery. Our chatbot supports submission of new descriptions of items; however, we need a way to verify they do not contain misinformation or abuse and contribute to the collections we display. This type of curation or review process is challenging when we do not hold any personal data on the users to verify their identity. To resolve this, we have developed a chatbot to interface to the social-coding platform GitHub. This not only provides provenance of all changes to data but also provides a process of review that is well established in software projects.