Cataloguing is a fundamental practice that enables access to archives. It creates greater intellectual control over a collection and is a key first step in ensuring a collection is accessible by researchers. The second step, is publishing it online. Online access to collections maximises the chances that your archive catalogue will be seen and your collections accessed by researchers who may be interested in studying them. It also provides the foundation for developing your collections and allowing them to be used in different ways by different audiences – in storytelling, for example. Given that it’s 2018, you’d think that online access to collections would be a simple option available to all. However, many barriers remain, which is one of the key reasons we developed Manage Your Collections – as a way for those who have no other means of making their collections data available online.
We began with a custom, ISAD(G) compliant Excel template, that users download, fill with catalogue data and upload to Discovery. Since we began recording statistics on data uploads, 148 collections have been added to Discovery via MYC in this way. However, we realise this may not be everyone’s preferred option and to enable Manage Your Collections to benefit as many user bases as possible, we have been developing a new feature – the metadata mapper. Using our template can be an extra, and lengthy, step for those archives who already have catalogue data: to take spreadsheets of data that already exist and copy and paste into the MYC template is not the most efficient way of using the tool. To enable a more efficient and streamlined process for these users, we created the metadata mapper.
The Metadata Mapper
So, what exactly is the metadata mapper? Simply put, it facilitates a one-off process in which archives can map their catalogue field names to Discovery’s, making uploads to Discovery via Excel easier. Users can upload their own spreadsheets (.xslx and .tsv files accepted) in ‘Add a Collection’ and once the file is uploaded, a new step is introduced – ‘Map fields to Discovery’.

Map fields to Discovery button
This button will take users to the mapper page. Discovery’s catalogue fields are displayed in the left-hand column, with the catalogue fields taken from the uploaded spreadsheet displayed in the right hand column. Users then select a Discovery catalogue field, the corresponding field from their spreadsheet and hit ‘Match’ with the two matched metadata fields appearing in column 3. Users can map as many fields as they choose; the minimum needed are the five required Discovery fields – Level of Description, Title, Name of Creator(s), Scope and Content, Reference code – and either ‘start date’ and ‘end date’ or covering dates for the material.
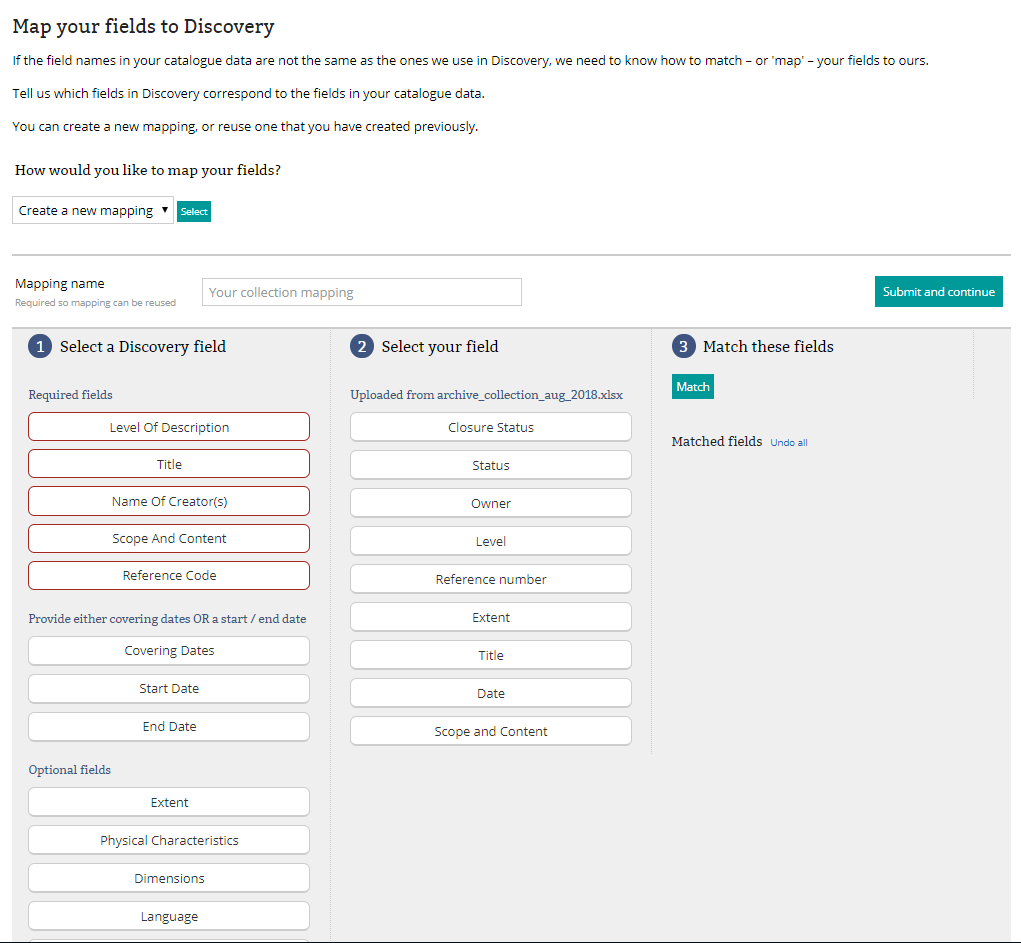
The MYC metadata mapper interface
It is possible to undo matches if fields are matched by mistake – by clicking ‘Undo’ under the field concerned, the headings are simply repopulated back to their respective columns.
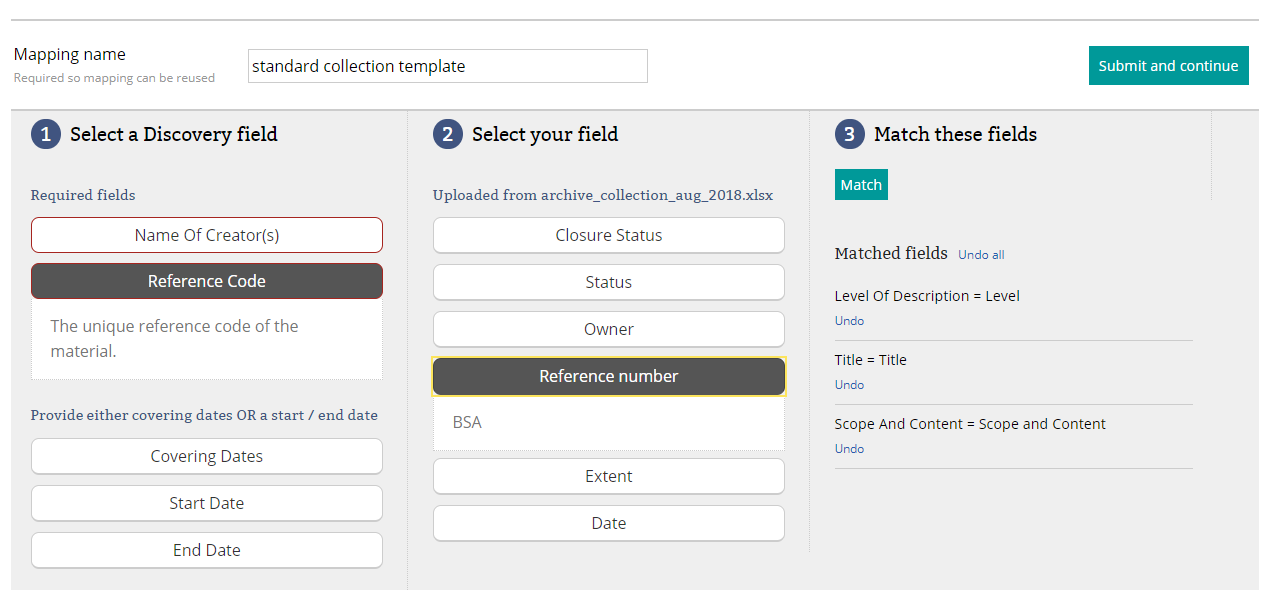
A mapping in progress
Realising that archives may have a uniform cataloguing process that routinely populates the same fields, we have enabled the ability for mappings to be saved and reused. So long as each spreadsheet uploaded has the catalogue fields in the same order as the saved mapping, users can select their mapping from the drop-down ‘How would you like to map your fields?’ – the option to save more than one mapping template is also available.
Once the mapping is complete and users click ‘Submit and continue’ they are taken back to the ‘Preview and Approve’ stage of the upload process where a sample record can be viewed before the collection is published.
Upload via the MYC Template
Upload via the MYC template is still an option for users of the tool – we realise that many archives have no catalogue descriptions at all and so cataloguing directly into the template is still and will remain an available option. What we have done with the development of the mapper is increase flexibility and usability of the tool for a wider spectrum of users, creating a streamlined process for archives to use existing spreadsheets or export data from their collections management systems, upload, map and publish their collections in a hassle free fashion.
If you are an archive service interested in finding out more about Manage Your Collections, please see the ‘Contributing to our resources’ page on our website or email the Manage Your Collections team at manageyourcollections@nationalarchives.gov.uk.
I am researching my family history – but more like a one name study from original sources. I have masses of data and some years ago there was a metadata introductory hour in Univ. Roehampton on a family history day and though I attended the option I wasn’t sure it applied to me. But the more data I acquire and try to collate the more I see the necessity for this. But this whole field is really new to me and I would need a study day, aimed along the lines of the ‘idiots guides’ manuals.