Our Research Exchange series features the work of researchers across The National Archives in which they discuss their new discoveries and their work’s potential for impact. The purpose of the series is to highlight and demystify the research we do and open it up to new ideas and discussion.
In November and December, to coincide with our upcoming Annual Digital Lecture, we will be publishing a series of blogs focusing on different aspects of digital research happening at The National Archives.
Our staff will be writing and reflecting on their research, discussing topics such as using AI in archives, using 3D Virtual Tech to access heritage collections, archiving citizen research projects, and much more.
Jake writes…
This is the second part of our interview with Mark Bell and Leontien Talboom, two researchers who have recently been using computational methods to explore the UK Government Web Archive (UKGWA). In this part, Mark and Leontien discuss the problems of getting access to the data they needed for their research, and how they would like to see computational access developing in future. You can read the first part of the interview here.
Getting access to the data you need to work with, seems to be a big issue with these sort of techniques. In your paper you talk about scraping content (extracting text and link data for further processing) from the web archive. Could you explain some of the issues around this, and what you were able to do with the data once you got it?
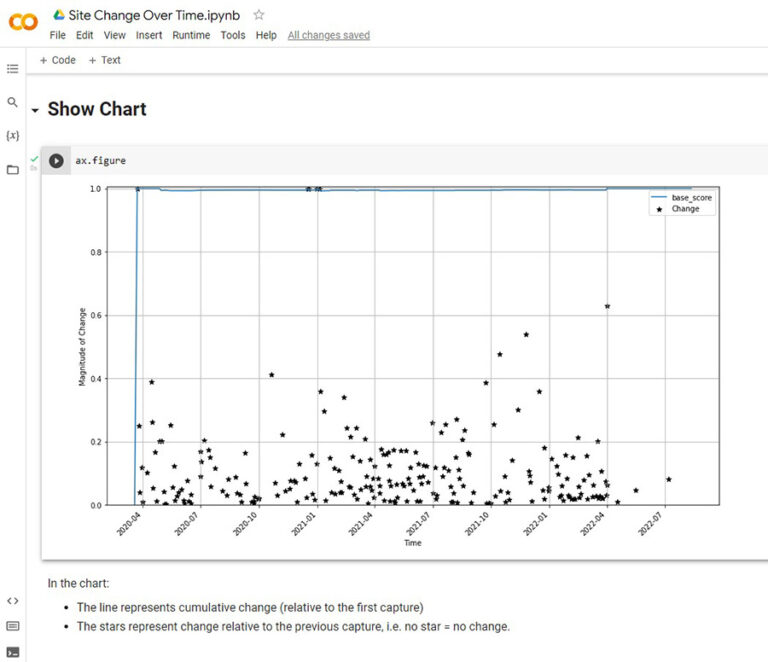
MB: Scraping feels like a stop gap solution because we’re effectively duplicating the process that created the archive in the first place. An alternative, such as computational access to archived WARC files, would require a massive infrastructure change. Scraping is not a scalable solution as the process of extracting content and links from a web page, especially in Python, is not that efficient. If we’re to scrape ethically then we also need to be considerate of the effect our activity has on the functioning of the web archive itself, so we need to limit the number of pages we access per minute. However, for small scale work it is a very direct way of accessing the content of the archive. There’s also a neat feature built into web archives that allows you specify a point in time and it will return the nearest snapshot, so you can narrow down the scope of your crawling that way. Once you’ve scraped a site though you have the full HTML, which means you can extract content for text analysis, and hyperlinks for networks. There are so many possibilities from there. There’s still data cleaning to be done though, such as standardising links, and removing boilerplate (menus etc.) from the HTML before extracting text. The thing I find most fascinating about analysing the web archive is change over time, there are lots of aspects to it – changes to content, design and the network.
LT: Scraping seems to be an interesting balance, especially when institutions do not have a scalable infrastructure in place to provide WARC files to users. It made it possible for us to pinpoint very exactly what we wanted from the material, without having to sift through everything for example. However, as Mark already pointed out, there are a number of ethical concerns around doing web scraping. Not only with overloading the system, but also around possible legislative and copyright issues. One of the main points that we made in our article (see part one) was how a Terms of Use can help institutions set up a number of rules/guidelines for users interested in web scraping.
At the UKGWA we are discussing different options for making our material more available for computational access. This could include APIs, extracted datasets, and Notebook-mediated access of the sort you’ve been experimenting. Which approach do you think would be most useful for researchers?
MB: All of the above! It would be nice to see one of our datasets being used by researchers for benchmarking, for example. I think Notebook-mediated access really lowers the technical bar and can be used both as a teaching tool and a jumping off point for creative approaches to access. API access, especially to clean data (e.g. a hyperlink API), would reduce the need for researchers to have to have to do all their own pre-processing which is very time consuming if they’re effectively all doing the same thing (e.g. extract text, extract links).
LT: Haha, totally agree with Mark. Seriously, just having anything available is useful. You would be surprised how creative people are if you provide any type of computational access.
What do you see as the future for computational access to GLAM collections more broadly? If you were designing a digital collection from scratch, how would you build in computational access from the start?
MB: I really like the non-consumptive approach where you take the tools to the data rather than extracting data and taking it home to work on. The HathiTrust pioneered this for copyright reasons but I see it as very practical. The web archive is 500TB and growing; the digital archive will grow at a massive rate over the next 10 years. Do we want researchers downloading terabytes of data or is it better to just run their code?
I also think we need to do a lot more to treat our collections as data and linking across collections. We touch on this in part one; although we can computationally access data in Discovery and UKGWA, they are not joined together as systems, nor are they designed with computation in mind.
LT: Infrastructure is important here, especially in regards to the scalability of this material. But there are other concerns that go beyond the technical implications when looking at computational access, especially around the ethical and legislative concerns of accessible collections. HathiTrust is a great example here, but it will also come down to a lot of advocating and explaining of why this type of access is beneficial and why it should be possible for researchers to do this. Also, computational access requires a certain level of abstraction regarding the documentation provided with it. So for example, it becomes important to know what processes were used to convert certain files, or it becomes important to know why certain parts of the collections are digitised and others are not. Or in the case of the UKGWA, it becomes important to know why some web pages are captured multiple times a year, and other are not.
Do you have a favourite page or other content in the UKGWA?
MB: Well, for some reason salt.gov.uk has appeared in just about every presentation I’ve ever given. I think because it’s quite a small site but seems to have lots of features which fit with my experimentation, such as appearing in several domains over its lifespan. There are also some really fun pages such as the Beefy & Lamby campaign, and Keith Chegwin singing a song about chips, which you wouldn’t expect to find in a government archive.
LT: Apparently, there used to be a British Potato Council, which we surprisingly came across during the CAS workshop when doing network analysis and made us laugh quite a bit. Seems like a very British thing to have, a council dedicated to potatoes.

Finally, what are you working on now?
MB: For current work (once I’m back from holiday!), I’ve got a number of areas of interest which I hope to make varying levels of progress on: experimentation with open source handwritten text recognition, further development of a Library Carpentries ‘AI for GLAM’ lesson which we (The National Archives, British Library and Smithsonian) hope to progress to a Beta release, Data-Centric AI (for archivists) which involves manipulating data to train a fixed machine learning model, and continuing to look at change over time in the web archive. That should keep me busy!
LT: I am currently in the final stages of my collaborative PhD and have started working as a Web Archivist based at Cambridge University Libraries on the Archive of Tomorrow project, which is looking at the spread of health information in the online space. Recently I finished working on the Computational Access Guide with the Digital Preservation Coalition, which is part of my Software Sustainability Fellowship.
The Jupyter Notebooks discussed in this interview are available from Github and the accompanying article is ‘Keeping it under lock and keywords: exploring new ways to open up the web archives with notebooks’. The UK Government Web Archive preserves the websites and social media accounts of central government, and can be accessed by anyone online.