Our Research Exchange series features the work of researchers across The National Archives in which they discuss their new discoveries and their work’s potential for impact. The purpose of the series is to highlight and demystify the research we do and open it up to new ideas and discussion.
In November and December, to coincide with our upcoming Annual Digital Lecture, we will be publishing a series of blogs focusing on different aspects of digital research happening at The National Archives.
Our staff will be writing and reflecting on their research, discussing topics such as using AI in archives, using 3D Virtual Tech to access heritage collections, archiving citizen research projects, and much more.
Jake writes…
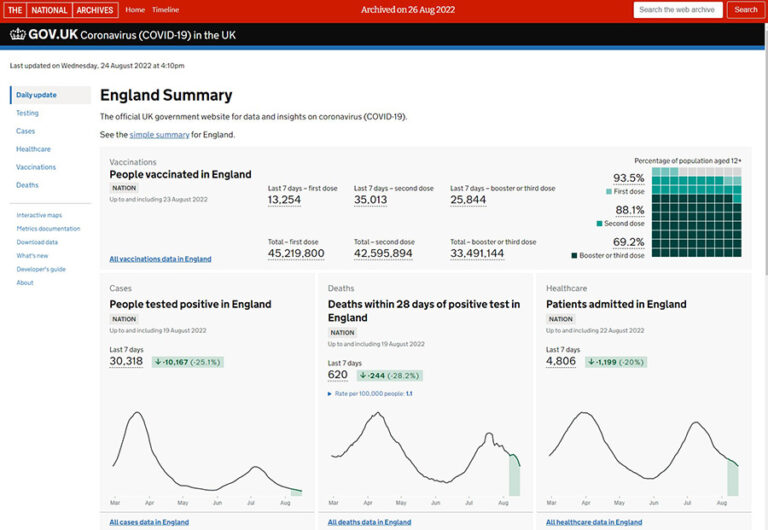
The UK Government Web Archive (UKGWA) preserves the websites and social media accounts of central government, and can be accessed by anyone online. In this two-part interview, Jake Bickford, Web Archiving Assistant at the UKGWA, speaks to two researchers who have recently published on using computational methods to explore the UKGWA. Mark Bell is Senior Digital Researcher at The National Archives, and Leontien Talboom is a National Archives/University College London collaborative PhD researcher, and Web Archivist at Cambridge University Libraries. In this, the first part of the interview, Mark and Leontien discuss their motivations for working with web archives, some of the challenges web archives present to researchers, and how they used Jupyter notebooks to address some of these issues.
How did you first get interested in working with web archives? And what interested you in the UKGWA in particular?
Mark Bell: My first exposure to the web archive was while preparing datasets for a Computational Archival Science (CAS) workshop in 2018. We already had text datasets so I extracted hyperlinks from web pages so that we could have a team working on network analysis. I chose UKGWA because we wanted to work with our own collections but it also has the advantage of being openly accessible. What I find particularly interesting about it is the breadth of material – there’s the core central government estate but then there are thousands of sites around the periphery which can be about almost anything.
Leontien Talboom: Similar to Mark, my first real exposure to web material was during the CAS workshop in 2018, when we did network analysis on the web material. This was the first time that I realised how interesting and complex web archives were. Not only was it born-digital material, which is one of the focuses of my PhD work, but it also has a complex temporal aspect to it which makes it fascinating. The UKGWA was of particular interest, as it was (and still is) one of the only fully openly accessible born-digital collections out there.
How do web archives differ from other archival material you have worked with? What advice would you give to researchers coming to web archives for the first time?
MB: I find the immediacy of it really interesting. The rest of the archive is at least 20 years old but something could have happened this morning and already be archived. The other big difference is the coverage which in some cases (e.g. COVID-related pages) must be approaching 100% of versions of a web page, whereas the traditional archive undergoes selection (~10%). I think my advice is to browse before you search and use the timelines to get a feel for the frequency of captures for different sites.
LT: It differs in the sense that it is all very new material: like Mark says, some of these websites are being archived today, whereas other ones date back a couple of decades. What is fascinating also is how there are multiple snapshots of the same web page over a number of years, making it possible to compare change. Not only comparing the content of the material, but also for example the changing style choices of web pages and technologies used to create these pages. A tip for researchers getting started with this material is to understand how web archives are created. This really helped me at the start, just releasing that these are live captures of the web, not just archived HTML/CSS pages that a depositor has given to the archive.
Why do you think more traditional methods, such as keyword search aren’t – by themselves – adequate for grappling with web archives?
MB: The scale means you generally get too many results to sift through, and the ‘duplication’ (quotes because they’re not exact duplicates) mean you get even more results. Secondly, the results are not sorted intelligently as they would be with a search engine, which means the most relevant result for your search is unlikely to be on page 1 – it may not even be in the first 100 pages.
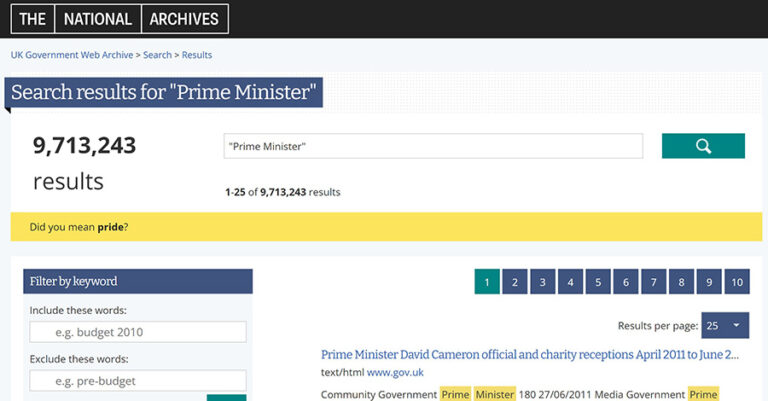
LT: Totally agree with Mark here, also just a full text search does not necessarily make it possible to work with this material in an easier way. As searching for terms such as ‘Prime Minister’ would give millions of results. The search results provided are then not necessarily relevant to prime minister, but will just flag any mention of it, even if it is on a web page about something totally different. This can be frustrating for users of the web archive.
As part of your recent paper, you created Jupyter Notebooks to facilitate computational access to the UKGWA. Could you tell us what that involved and why you went for that option?
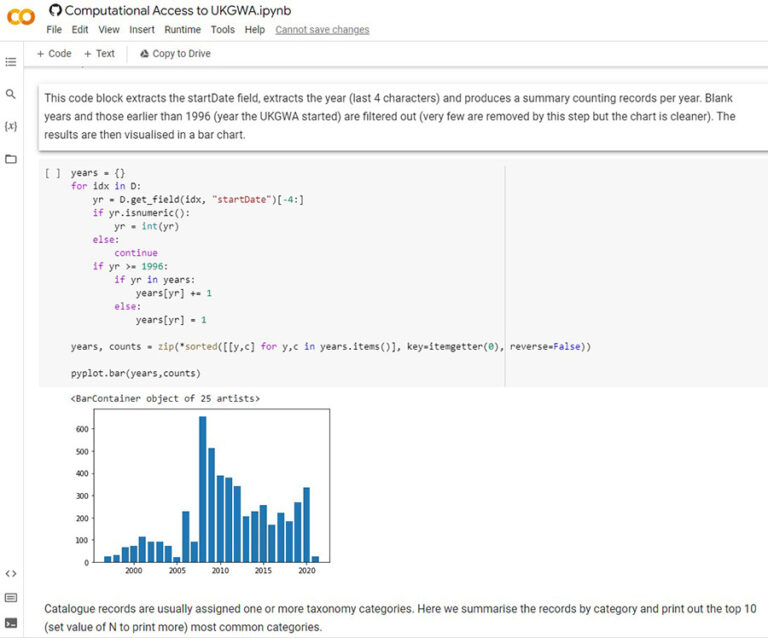
MB: We already had experience of using Jupyter Notebooks hosted on Google’s Colab platform for the Machine Learning Club we ran in 2020. They provide an environment for running Python code which is accessible through a web browser removing the complexities of installing software, and allowing you to just jump straight into the analysis. A Jupyter Notebook consists of a mixture between descriptive text and boxes containing code to be executed at the click of an arrow. The code can in turn produce textual output, tabular data, and visualisations. This means you can produce and share a fully documented and reproducible analytical workflow. They are already accepted in the web archiving community thanks to the GLAM Workbench.
It still wasn’t quite as simple as chucking some code into a Notebook though. We also wanted to facilitate those without Google accounts by providing the option to use the MyBinder service, which meant coding around some of the differences between the two platforms. Some of the code used was quite complex and didn’t necessarily add to the narrative (e.g. text indexing) so we hid that away behind one-line functions, although the code itself was openly viewable in Github. We also used extra widgets like dropdown boxes to reduce the need for users to edit code to try different parameters out. The point was to show just enough code to demonstrate the intricacies of working with the web archive while not overwhelming the user. A lot of those intricacies were discovered while writing the Notebook so it was an informative exercise.
LT: Just to add in a more general note, Notebooks are providing an infrastructure to explore archived collections in a different way and it does need a bit of fiddling to get it right. The main worry now is the sustainability of this approach, considering that in the short span of working with these Notebooks we already ran into several issues with Google updating their Colab platform. However, for the time being they are a great option for the community. We just hope that our article adds to this encouragement of thinking about a more robust infrastructure to provide computational access to material.
One approach you took was combining different sources of information such as Discovery and the UKGWA A to Z list of archived websites. What was the thinking behind that approach and how did it work out?
MB: The web archive is catalogued in Discovery but not in an integrated way – it feels like each site is just another box tucked at the end of a shelf. So I wanted to bring the two together properly. The descriptions in Discovery aren’t very informative compared to those in the A-Z, but Discovery has the department and the added bonus of an administrative history for about a third of sites. Bringing them together highlighted a couple of things for me: firstly, it was the immediacy of metadata generated by an automated process (crawling websites) and the slower time, manual process of cataloguing. Secondly, it was reminder of how the catalogue captures different data to the UKGWA – the collection may hold records which aren’t in the web archive, for example. The administrative history is a good example of this as it tells a different story to what you might get if you just described what was contained in a website. We experimented with comparing machine learning generated summaries of a site with the administrative history in the notebooks.
LT: For me this was an important one, as many people within our field worry about the obsolescence of the digital archivist, as the machines may be taken over the work. But this Notebook highlights how both metadata from the catalogue and from UKWA itself are useful and both types of metadata provide a different perspective on the material.
The second part of the interview, discussing the problems of accessing data for computational research and Mark and Leontien’s thoughts on the future of the field, will be next week. The Jupyter Notebooks discussed in this interview are available from Github and the accompanying article is ‘Keeping it under lock and keywords: exploring new ways to open up the web archives with Notebooks’.