Are you a regular user of the UK Government Web Archive? If so, you might have noticed some changes. If you’ve never used the web archive before, now could be the perfect time to take a look.
Following a procurement exercise we awarded the contract for providing our web archiving service to MirrorWeb. Over the last few months we’ve been working with the MirrorWeb team to relaunch the web archive. We’re extremely excited to show you the outcome.
The improvements were driven by the results of a comprehensive user research project we carried out in late 2015, along with general modernisation of the technology used to provide the service.
A new look
The Web Archive’s home page will soon have a new look! The new design uses The National Archives’ WordPress template which has an improved layout and typography compared to the previous design, and is consistent with the rest of our web pages.
We now have only one image, in the header section, to make the rest of the content pop out and to make the page ‘clutter free’. The new template features only six sections and everything you want can be found within them.
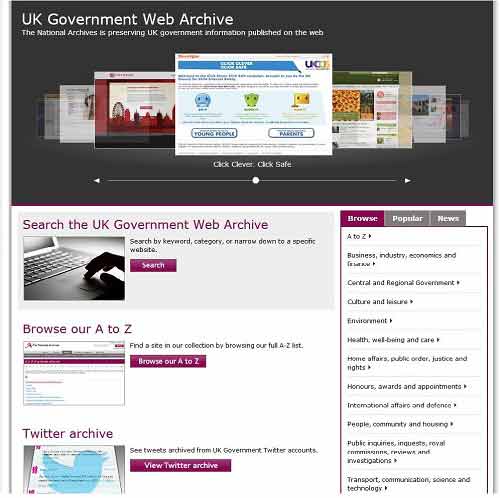
The ‘old’ web archive
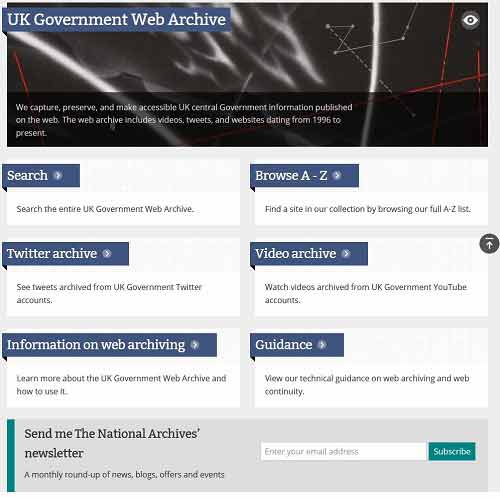
How the web archive looks in 2017
The new look will also apply to the Twitter and video pages. Both these pages will have large and spaced out thumbnails with subtle effects when you hover over them. The new Twitter and video access pages will be launched within the next few weeks.
A lot of these changes were based on the conclusions of last year’s user-study. What we have now is the outcome of implementing the findings of the study, paying attention to detail, and working closely with our very helpful Web Team.
We paid attention to the small details as well as the big features to produce a smoother user experience. We’re continuously working to improve this product so please let us know if you have any suggestions for future versions.
New technology
In line with our Digital Strategy the Web Archive and associated services such as full text search will now be hosted in the Cloud. The change in hosting arrangements aims to make the service faster and more reliable. Additionally, it will make it easier to transfer data, for example to researchers who wish to undertake large scale research on our collection.
We will also be using state of the art technology to capture websites and make the archived websites accessible. This includes using the most up-to-date stable version of the Heritrix web crawler to capture websites and using pywb to play back archived sites. Moving to pywb has already fixed many access problems which existed in the ‘old’ web archive.[ref]An access problem occurs when we have captured a resource successfully but we cannot make it available in the web archive due to a technical limitation.[/ref]
Search
The ‘old’ web archive full text search was unreliable and its functionality was limited. One of the strongest messages which came through our user research project was that search needed to be improved.
The new search is running in the cloud and uses up-to-date technology, which should make it much more reliable. Additionally OCR (Optical Character Recognition) software is run on pdf files as part of the indexing process so it is now possible to search the contents of documents which were scanned from paper originals. New functionality will be introduced to search in the coming months including the ability to facet search results by government department, category and year of capture. Newly captured sites will be available to search much more quickly as the full text search index will be updated monthly rather than quarterly.
This week we have gradually been transferring over to the new service. During this time some users have been directed to the new web archive at random. This is a seamless process as all Web Archive web addresses remain the same. By the end of Friday 30 June all users will be directed to the new service.
During the transition period full text search and the Twitter and video archives will be unavailable. We expect all services to be up and running within the next few weeks.
Please take a look at the ‘new’ Web Archive and let us know what you think either in the comments or by emailing: webarchive@nationalarchives.gov.uk. We’re looking forward to hearing for you.