Our Research Exchange series features the work of researchers across The National Archives in which they discuss their new discoveries and their work’s potential for impact. The purpose of the series is to highlight and demystify the research we do and open it up to new ideas and discussion.
This month and next, to coincide with our upcoming Annual Digital Lecture, we will be publishing a series of blogs focusing on different aspects of digital research happening at The National Archives.
Our staff will be writing and reflecting on their research, discussing topics such as using AI in archives, using 3D Virtual Tech to access heritage collections, archiving citizen research projects, and much more.
In our second blog of the series, Hazel Jell continues her discussion on the Our Heritage, Our Stories project and the Observatory.
Our Heritage, Our Stories: Visualising, mixing and sharing community-generated digital content in the Observatory
Our Heritage, Our Stories (OHOS) is an AHRC-funded discovery project within the Towards a National Collection programme, addressing the challenge of ‘critically endangered’ community-generated digital content (CGDC). CGDC resources are commonly hard to find, isolated, under-utilised and at risk of disappearing.
OHOS is a multidisciplinary team of researchers in digital humanities, archives, history, linguistics and computer science, with research software engineers (RSEs) from the Universities of Glasgow and Manchester, and The National Archives.
At The National Archives, we’re building the ‘Observatory’ – a public-facing interface to make CGDC available for anyone to access, reuse and remix.
The CGDC will be transformed and connected as linked open data (LOD) – a method for connecting disparate data sets and publishing information online by representing knowledge as a graph structure. The transformation will be completed by AI experts at the University of Manchester. The Observatory will host the enriched data linking back to the CGDC, present it, and allow interaction with the knowledge.
Researching and designing
To build the Observatory we need to know both what is possible and what is useful. To understand this we have been carrying out research and will be co-designing with project stakeholders.
Our research has centred on existing interfaces, tools and technologies across cultural heritage and other sectors that overlap with our aims. We have discovered popular tools for interrogating historical data, such as timelines, maps and filters to find specific areas of interest and discover ‘new knowledge’.
We have also been researching existing personas in the archival sector and crowdsourcing projects to understand our potential users, their motivations and frustrations. Personas are fictional characters based on research to represent our different audiences, which help us to focus on specific users and needs rather than generic during our design.
We are using industry-standard tools – Miro and Figma – to produce and share our design ideas. These enable us to collaboratively design, share, feedback and refine ideas among the project team before turning them into defined work for the RSEs to develop. The ideas we are generating now will be used to support co-design, demonstrating ‘the art of the possible’ and encouraging creative thinking.
When the project’s workshops kick off, which will be announced on the OHOS website and social media channels, we will begin our co-design activities. Co-design is an inclusive, creative and participatory process to actively involve the community as equal partners in the design, ensuring we create tools that are useful and intuitive for anyone using the Observatory. Activities will involve public surveys, followed by design workshops, user testing and feedback as a cycle to continually improve the Observatory.
Visualising
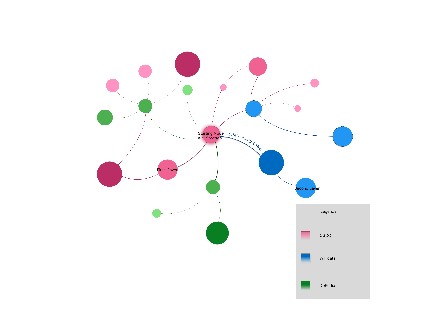
To visualise the knowledge, we are experimenting with the traditional network graph display of LOD, plus timelines, maps and a 3D gallery.
We are working on several ‘prototypes’ of the Observatory to explore these visualisations. We are developing ways to explore and interact with the network graph; to change the data shown with user-friendly controls, to highlight relationships, and to identify sources of data where the CGDC is enriched from sources such as Wikidata.
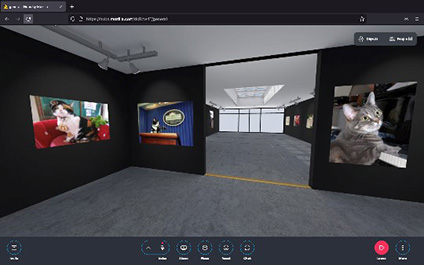
The 3D prototype is visualising images and associated text in a gallery-style view that anyone can walk around virtually and share additional knowledge through an annotation chatbot.
Remixing
Ideas for remixing focus on the tools someone in the Observatory could use to incorporate, connect and download new knowledge. While we are still preparing for the co-design activities, ideas for exact tools remain fluid.
‘Remixing’ will allow content owners to connect their community content with the enriched CGDC data to find new relationships. Anyone will also be able to annotate the data, either to correct relationships or add new based on personal knowledge.
What next?
We are designing and building the minimum viable product (MVP), which will be the first iteration of the Observatory with the minimum features and functionality required.
Alongside the wider project team, we will be carrying out user research and engagement activities to design and get feedback on the first, and future, iterations.
We are continually gathering, designing and prioritising new ideas.
If you would like to share ideas or get involved in the project, email research@nationalarchives.gov.uk.
To keep up to date with the project, follow @OHOS_NatColl on Twitter, or check out the project website.