The National Archives’ Digital Strategy (2017-19) identifies the challenges we face as we become a second-generation digital archive. The strategy envisions an archive that is ‘Digital by Design’, able to preserve and provide access to a wide range of rich digital records which better reflect the workings of a digital government. In particular, the strategy highlights the need for a new way of providing access to digital archival records.
The digital records we’ve received so far are more diverse than physical records. They are not just documents but can include all sorts of other content, from threaded discussions using a web-based tool to video, websites, structured datasets or even computer code. These records can be complex and often consist of different components, potentially with different creators and owners. And we know that ever more specialised formats will need to be added to our collection over the coming years.
However, these new digital objects are public records in the same way as the paper files they have replaced, and we need to make them at least as accessible as analogue records are now. In doing this, we cannot simply take the standards, processes and tools we use in the paper world and apply them in the digital world – the two are significantly different.
We have started exploring how we can provide access in a new way which has been designed from the outset to fit the way our users want to work with digital records today and will support how they may want to work with them in the future. A key difference is that, while we will still offer a ‘view’ of individual records for our ‘readers’, we must also make records available for computational analysis, enabling our ‘data users’ to work with records at scale and ask very different types of research questions.
At the same time, we will actively process the collection ourselves, to enrich descriptions and contextualise the records. This activity will produce information of a different size and shape to our traditional catalogue descriptions. For example, we can imagine contextualising records through their links to other resources, often held by other institutions, or through enriching descriptions to make the records more discoverable – or by applying probabilistic techniques that embrace the uncertainty that is typical of historical records.
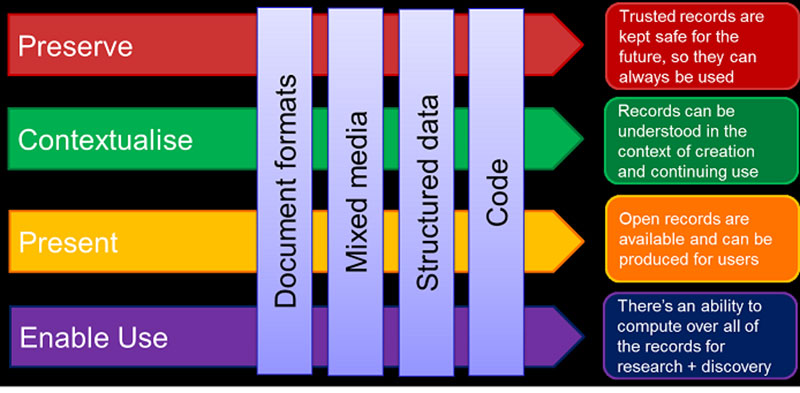
There are four categories for the value the digital archive offers its users: preserve, contextualise, present, enable use.
As we’ve started work on this, a key building block that we’ve identified is the need for a model that describes our records as data. Our existing catalogue simply will not hold the range of information we now need to manage: we need to adapt to accommodate a much richer understanding of our records.
In doing this, we want to learn from others with similar challenges, re-use work that has already been done and innovate to create new approaches where needed. There are a lot of data models out there. Some of these were created with archival collections in mind (such as RiC and PREMIS) while many come from other domains with similar challenges (such as METS or FRBR). There are even models which try to bring together multiple approaches (EDM). All of these offer a particular way of thinking about or describing digital collections.
We are currently looking at the kinds of information we want to hold – from metadata that was created by the originating government department/organisation, or values that are intrinsic to the digital objects (such as geocoding in images), to properties later externally derived about the objects either singly or in aggregation. Our model will embrace uncertainty, temporal variation and user-contributed content.
If you are working on similar issues, or you have a particular interest in any of the themes outlined above, we would love to hear from you. Please either comment below or email discovery@nationalarchives.gov.uk.
Wonderful work! You may be interested in the ‘Always Already Computational: Collections as Data’ project. https://collectionsasdata.github.io/
Thanks for your comment Thomas. It’s great to see that other archives and libraries are thinking about these challenges too.
It is with great interest that we are reading your blog post. We are facing the same challenges and as it seems, thinking along much of the same lines.
The National archives of Norway has for the last 40 years been deeply involved in shaping the way the public administration has created, organized and stored its records. Our ambition is to still influence record management and information management in the public sector, but we probably have to do that in a very different way than before. The Noark-standard (older brother of Moreq) has shaped the thinking around records management for more than 30 years, for better and for worse. It may still be a tool for securing both transparency and some of our collective memory. However, as the diversity in the creation and use of information grows at an exploding pace, we need new tools that are flexible and adaptable.
And we need a whole new way of thinking as well, perhaps with even greater emphasis than before on making the data available. One of the tools we are developing to help us tackle this, is a Reference Model for Archive/Records. It is not finished yet, and at this stage, it is meant purely for communication purposes. In doing so, we also seek to open our domain to other professions, such as data protection, data governance, enterprise architecture, information security etc.
We would be very interested in gaining better insight into your model and the rationale behind it. We also think it would be interesting to compare our model to yours and understand how they differ and why. We hope that you find this useful and would consider further dialogue.
Best regards
Øivind Langeland and Tor Anton Gaarder
National Archives Norway
Thanks for your comment. I read your draft reference model with great interest. I think it could be very interesting to compare models!
[…] we touched upon in our recent blog post, we now need a model that describes our records as […]
Great work.
I think that in any model the distinction between digital and physical records/items/things and their attributes is essentially redundant, because we are about describing content and context of the data. We are describing the wine not the bottles, but I suppose the bottle is an attribute and could be described, too.
I think also any model needs to include the ‘business’ – the entities, etc. that are required to deliver, maintain, present, preserve, etc. the data about the ‘items’ we have. I mean here the services that an institution provides.
One thing I am interested in are the entities required for management of interfaces to any system. This includes the presentation of information, so that for example in an archival context, you can see the relationships – over time (predecessor/successor agencies or series) and between items (controlling/controlled relationships), etc. As well you can present this information in particularly ways, for social media, online exhibitions, etc. You don’t have to reformat the data each time for each platform that you present it on.
I would love to see entity relationship modeling, or the modeling used for Graph databases used more widely. Archivists, librarians, and any other profession work with metadata; however the metadata seems to be a mix of entities, attributes and values… so there is an exercise to do to sort out the entities from the attributes… the forest and the trees…