The 19th century saw a number of global cholera pandemics, beginning in India and spreading west. The British Isles were hit during the second global cholera pandemic (1829-1837). Cholera arrived in Gateshead via ship in October 1831. The epidemic spread over the following year, leaving around 52,000 dead.
![reatment of the Premonitory [warning] Symptoms of Cholera
…
4. In a very large Majority of Cases, the Attack of Cholera is preceded by a Looseness of Bowels of longer or shorter Duration, say Twenty-four Hours. It is in this stage that remedial Assistance is most efficient, and that Life may be saved with the most Certainty, by checking the Disease in its Commencement. When, therefore, the Bowels become relaxed without an obvious Cause, where Cholera is prevailing at the Time, the following Measures should be adopted without Loss of Time:
5. In the Case of Adults, previously healthy, let Blood be taken from the Arm to Eight or Ten ounces, or by Ten or Twelve Leeches to the Pit of the stomach, or by Cupping.
Should the loose Motions of a darker Colour than natural, give Two Pills of Form No.2., and Four Hours after a Tablespoonful of Caster Oil, floating on Half a Wine-glass-full of Gin and Water, Brandy and Water, or cold Coffee, with Ten Drops of Laudanum [opium used as a pain killer and sleeping aid] if there be griping Pains. Confine the Patient strictly to Bed, and give the following Draught at Night:- Cinnamon or Peppermint Water, Half an Ounce; Laudanum, Twenty-five Drops
…
Let the patient drink cold water or iced water if it can be had, allowing no more than two or three table-spoonfuls at a time, or bits of ice the size of a nut may be given to be swallowed whole, to allay the burning sensation at the pit of the stomach. Let bags or stockings filled with heated bran or sand be placed along the patient’s spine or sides, and feet warmers applied to his feet. Let him be kept still, wrapped in warm blankets, but not oppressed with heat or coverings, particularly over the chest and neck.](https://cdn.nationalarchives.gov.uk/blog/wp-content/uploads/2020/06/01111457/Pc1_113_2-treatment-1832-768x551.jpg)
In response to this the British state took a relatively (at the time) unprecedented step – setting up a Central Board of Health to deal with the outbreak. The National Archives holds the Board’s records. It was disbanded after the infection began to dissipate in 1832.
Cholera returned to the British Isles in 1848. The outbreak of 1848-1849 placed the deadly consequences of England’s unchecked and badly planned urbanisation and industrialisation in stark relief; over the course of around a year it left more than 53,000 people dead. Many of the deaths would have been avoidable if basic sanitary measures were in place.
Faced with the undeniably filthy condition of England’s many neglected towns – replete with houses that were described by one Yorkshire official as ‘mere pigholes not fit for human beings’[ref]Letter to The General Board of Health from John Wilton, Guardian of the Poor, Castleford, [Yorkshire], 1849 Dec 14. Catalogue reference: MH 13/46/116.[/ref] – the Public Health Act 1848, which allowed for the establishment of a total of 1,010 Local Boards of Health throughout the country, overseen by the General Board of Health in Whitehall, was passed.

The 272 bound volumes of correspondence between the General Board of Health, Local Boards, sanitary officials across the country, members of the public and people reporting on cholera outbreaks, treatments and preventions both at home and abroad can be found in The National Archives record series MH 13.
Each item of correspondence is now described in detail on Discovery, the result of a Wellcome Trust-funded project. There are 89,298 of these descriptions. Together, these provide researchers a way to begin to establish the local and national dynamics of sanitary reform and disease prevention in the mid-19th century.
‘Distant Reading’
But how do we begin see the whole picture that these records collectively paint? It would be a challenge for any human to read, remember and analyse the hundreds of thousands of words these catalogue entries collectively run to, let alone the likely millions of hand-written words in the records they describe.
One way is to use machine learning to conduct a ‘Distant Reading’: using a computer to ‘read’ a large corpus of texts, then mapping them, tabulating them into graphs or otherwise visualising them. This stands in contrast to a traditional ‘close reading’ – as the careful, sustained interpretation of a brief passage of a text[ref]For more information on Distant Reading, please see: Franco Moretti, ‘Conjectures on World Literature’, New Left Review, Vol. 1, Jan-Feb 2000, pp. 54-68. S Jänicke, G Franzini, M F Cheema and G Scheuermann, ‘On Close and Distant Reading in Digital Humanities: A Survey and Future Challenges’, Proceedings of the Eurographics Conference on Visualization (EuroVis) (2015), ed. R Borgo, F Ganovelli, and I. Viola.[/ref].
Latent Dirichlet Allocation
One such set of methods to distant read large corpuses of text are referred to as topic modelling. In topic modelling computers use statistical calculations to place texts into subject groupings, or topics.
A simple kind of topic modelling is term frequency – inverse document frequency or tf-idf, which accords more importance to a word in a document within a collection or corpus based on a statistical model of it occurrences in an individual document compared with its comparative scarcity across the whole corpus. Importance is therefore accorded to distinctive words as opposed to universally common ones like ‘the’ or ‘at’, so the words with a high tf-idf score are more likely to be salient to a document’s subject.
In this case though, we will focus on a method referred to as Latent Dirichlet Allocation (LDA).
In LDA we work under the assumption that each text has a latent (underlying) topic or subject – characterised by the distribution of words within it and across the corpus of other documents.
The user defines the extent of the corpus and sets the number of topics they want to emerge (say five, for instance) – the model then calculates the probabilistic relationships between each of these entities and then groups the documents by the topics it finds[ref]Latent Dirichlet Allocation was adapted from genetic analysis for text mining by David Blei et al. in 2003. See: David M Blei, Andrew Y Ng and Michael I Jordan, ‘Latent Dirichlet Allocation’, Journal of Machine Learning Research, No. 3 (2003), pp. 993-1022.[/ref].
Computing Cholera
I carried out my LDA modelling using Python, a programming language I’ve been learning.
The first step was data cleaning. The average MH 13 item contains one text field giving the folio (page) range of an item, its recipient, sender, and finally subject description (see below image, different sub-fields highlighted in different colours).
Due to the scale of the whole dataset (over 89,000 items), this blog only focuses on topic modelling the items dated 1848 on Discovery, of which there are 1,967.
!["Folios 545-546. To: The General Board of Health. From: S W Maryone, Clerk to the Commissioners, Chelmsford, [Essex]. A letter. Maryon state that the Commissioners for Chelmsford have received a unaminous vote at a public meeting of ratepayers in favour of the adoption of the Public Health Act 1848 in Chelmsford. Maryone asks to be furnished with information as to the process of adoption."](https://cdn.nationalarchives.gov.uk/blog/wp-content/uploads/2020/06/01114701/mh-13-description-example.jpg)
Using some Python code, these sub-fields were split into separate fields in a .csv file, discarding the folio range. The result is an output, where the ‘to’, ‘from’ and ‘descriptions’ are separate, so the descriptions can be modelled on their own.
Topic modelling
In this project the Python package gensim, which bills itself as ‘topic modelling for humans’, was used to carry out the LDA modelling.
Gensim makes the process simple – the complicated algorithm underpinning LDA is written for the user – who just needs to define the corpus of texts, how many times (epochs) the model should train itself for, and how many topics they want generated.
LDA results can be difficult to interpret in their initial form, so the Python package pyLDAvis was used to visualise the results of the MH 13 topic modelling.
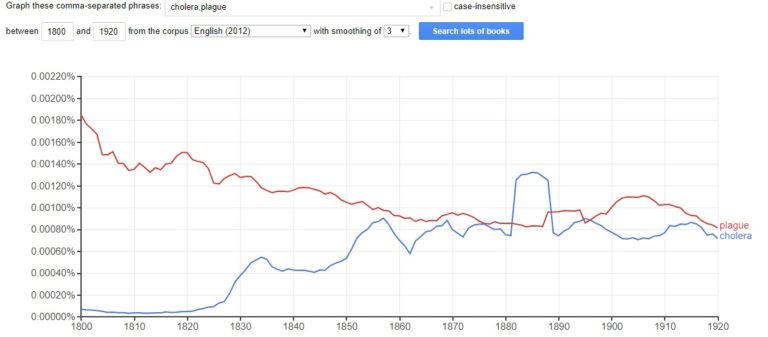
pyLDAvis produces a map showing the topic groupings across the corpus – the closer they are on the map, the closer they are in similarity. Then alongside this it presents a histogram of terms – first providing an overview of the most significant or salient terms across the corpus, then allowing users to click through each of the topics, seeing the words or bigrams (two words found together) calculated to be the most relevant by the model.
The pyLDAvis for the items dated in 1848 within MH 13 looks like this when viewing the whole corpus:
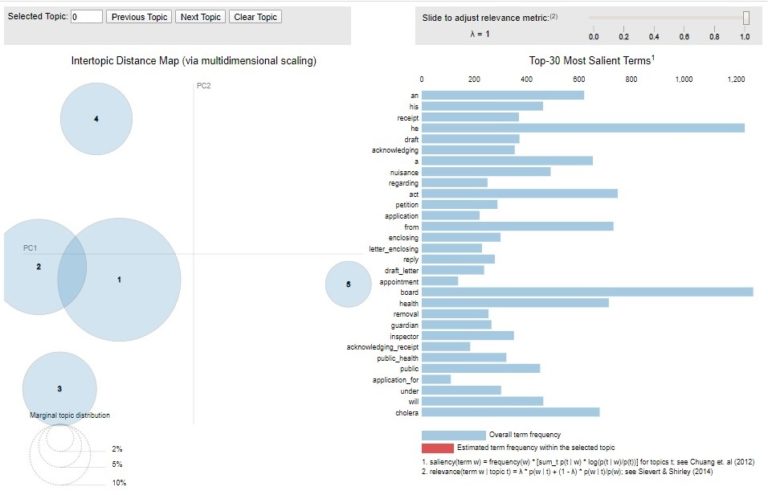
There are then subsequent maps and histograms for each of the five topics gensim generated. So what do they tell us?
Analysis
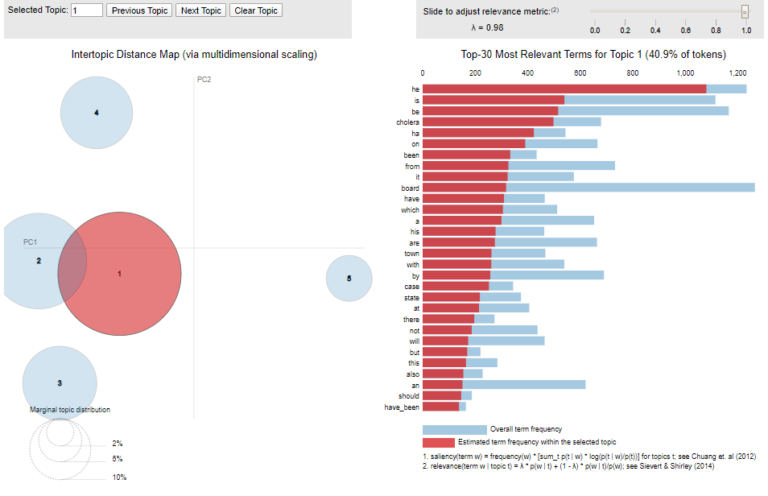
Topic 1, with the prominence of such terms as ‘cholera’, ‘town’, and ‘case’, represents a group of letters received by the General Board from localities reporting cases of cholera. The prominent size of the topic across the corpus (as visualised on the left-hand side map) is unsurprising – the General Board was formed during a cholera epidemic and the hysteria that accompanied this. If modelled for later years when cholera was not prevalent, one would expect this to be a less prominent topic.
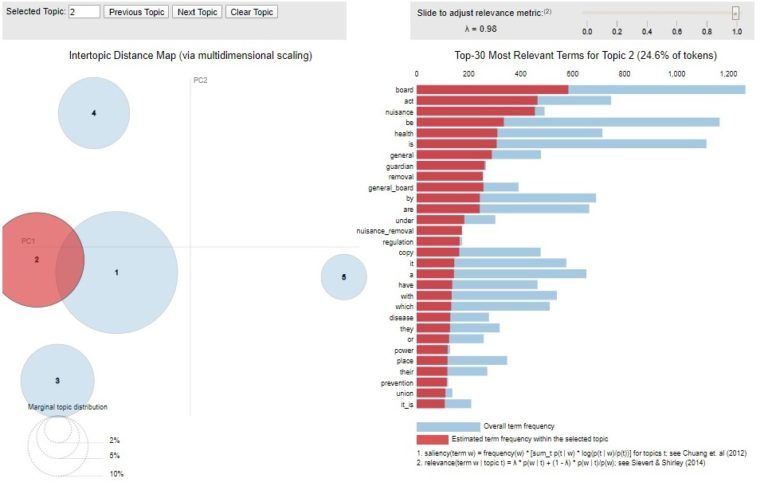
Topic 2 is grouped closely with topic 1 on the map and of a similar prominence. It is, however, distinct – highlighting the relevance of terms such as ‘nuisance_removal’ (a bigram picked up by gensim), ‘regulation’, ‘power’, ‘prevention’, ‘guardian’, and ‘union’. This topic seems to relate to Poor Law Union Guardians (local government officials with some sanitary powers) writing to the General Board to ask about their powers under the Nuisances Removal Act 1846 to deal with the cholera epidemic – a common theme in the early correspondence of the General Board.
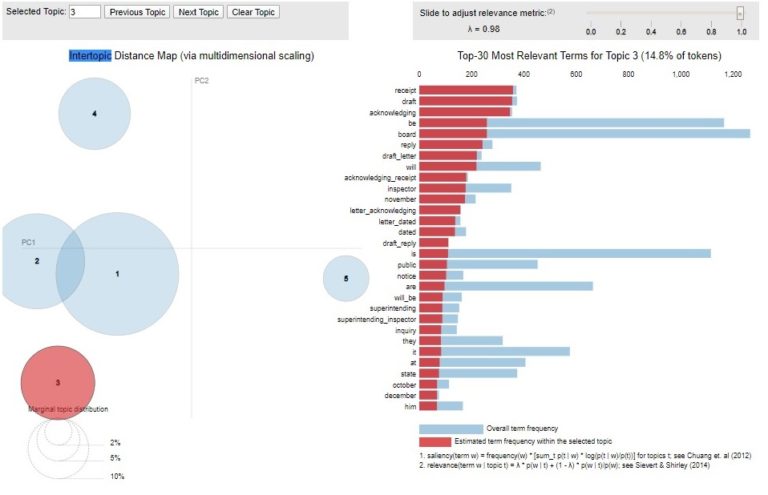
Topic 3 highlights the relevance of bigrams such as ‘draft_letter’, ‘letter_acknowledging’, ‘superintending_inspector’ (a group of roving sanitary engineers employed by the General Board). This topic is clearly the outgoing correspondence of the General Board, dealing with calls for public inquiries on the adoption of the Public Health Act in Districts.
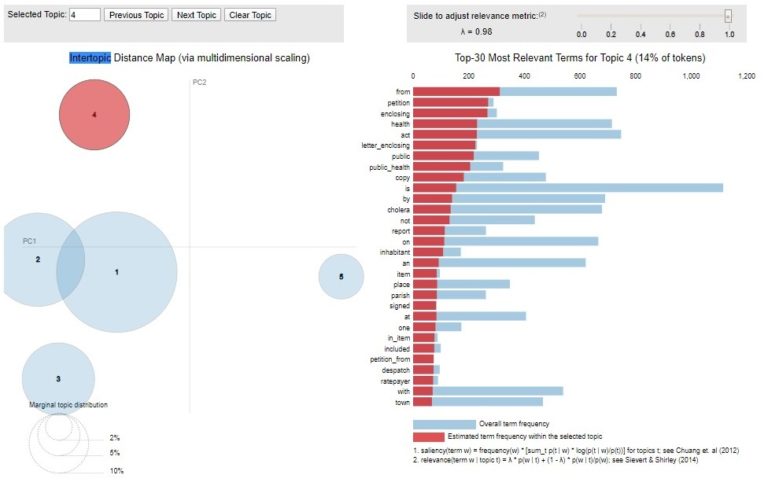
Topic 4 indicates the relevance of terms such as ‘petition’, ‘letter_enclosing’ and ‘public_health’ to the topic. This topic relates to petitions sent by localities to the General Board (hence the relevance of the bigram ‘letter_enclosing’) calling for the adoption of the Public Health Act there.
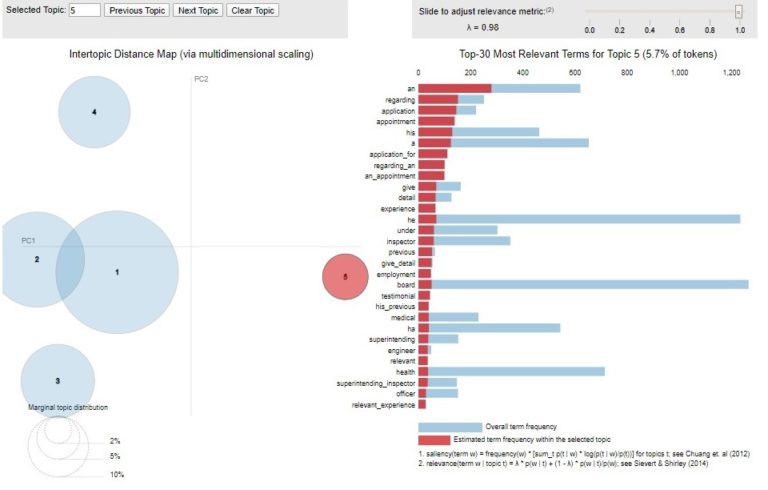
Finally, topic 5, the least prominent in the corpus, but a very discrete one, as its relative distance to the other topics on the map visualisation shows. With the relevance of terms such as ‘an_appointment’, and ‘application_for’, this topic accords with the job applications for superintending inspector and other positions the General Board received in the year of its formation.
So what? And what next?
Machine learning, with archival datasets, is often a lot of fun (not least when packages like gensim do much of the hard work). But the question remains after the algorithms ceases its sequence: what can the results tell us that we didn’t know anyway?
In this case, using the limited sample of MH 13 descriptions, I have not learnt much – I knew these were the topics of the letters I was analysing, as I catalogued a significant number of them myself. This sample has shown that the topics generated seem to match up with those I have observed though, which is encouraging.
But the visualisations do give us a sense of the scale and significance of the different kinds of letters – machine learning can accomplish this by ‘reading’ and computing a corpus of texts in minutes it would take a human hours to read.
Using these catalogue descriptions in this way quickly gives us an understandable impression of what the main features of the General Board’s work and correspondence was in 1848. This distant reading can therefore allow us to carry out a better-focused traditional ‘close’ reading of the records themselves.
In the coming months I hope to refine the code underlying this project, removing more common terms from the topic modelling like ‘his’, ‘a’, and ‘at’ which you will see cropping up in the visualisations above, and modelling the whole corpus of 89,000 plus descriptions.
Using the ‘catalogue as data’ (as my former colleague Richard Dunley has written about) to carry out computational analysis is a great way to take work carried out by archive professionals for one purpose – to make material easier to find by researchers – and do something different with it, treating it as a source of historical data in its own right, which informs our understanding of the material it describes and how we approach it.