Last month, I blogged about The National Archives’ collaboration with City, University of London, to visualise data from our collections in new ways. I wrote a second blog post about our collaboration with the University of Cambridge on how to enable complex analysis of large-scale datasets. A third blog post on our work with the University of Glasgow on Materialities of Digitisation was published earlier this month: it was also part of the research that comprises a series of digital experimentation workshops hosted by The National Archives throughout the 2017-18 academic year, in collaboration with different universities.
In this fourth and final blog post of the series, Professor Jane Winters and I will discuss the importance of approaching the web as a source of technological, sociological and historical research. This was the main focus of a workshop organised by The National Archives in collaboration with the School of Advanced Study (SAS), University of London. At the workshop, hosted at the SAS, a multidisciplinary group of experts came together to explore the various methodological and theoretical challenges – as well as opportunities – that occur when web collections are opened up for research and experimentation.
Speakers from a range of universities, heritage and cultural institutions, and government departments gave short presentations reflecting on the role of web archiving – not only in the traditional archival context, but also in the interdisciplinary research area of historical and digital research and innovation. With plenty of time for discussion, both speakers and attendees explored multidisciplinary questions that are rarely addressed together and can offer a creative, critical and innovative engagement with web archive practices. Among the research topics discussed – just to name a few – were: exploring changes in language over time; the ethics of open data use; the relationship between web archiving and digital preservation; and born-digital documents as essential sources for historical study.
The National Archives’ Tom Storrar vividly highlighted some of the challenges involved in web archiving, describing the problems posed by ‘crawler traps’ such as dynamic calendars. In one instance, the vast range of date options provided by a calendar, combined with multiple pagination, resulted in 44 million URLs to be archived in just one target host. Web archivists are constantly working to balance demands for completeness with what is reasonable in practical terms. Much of the discourse around web archives is concerned with their relatively limited use by researchers to date, so it was encouraging to be reminded by William Kilbride (from the Digital Preservation Coalition) that this is in fact a rapidly maturing field of research, where collaboration between researchers and archivists is yielding excellent results.
Finally, there was a demonstration by Anna Perricci of the potentially transformative effect of easy-to-use tools such as Webrecorder, which are already empowering individuals to build their own web archives, and may change the ways in which memory institutions develop their collections and collecting practices.
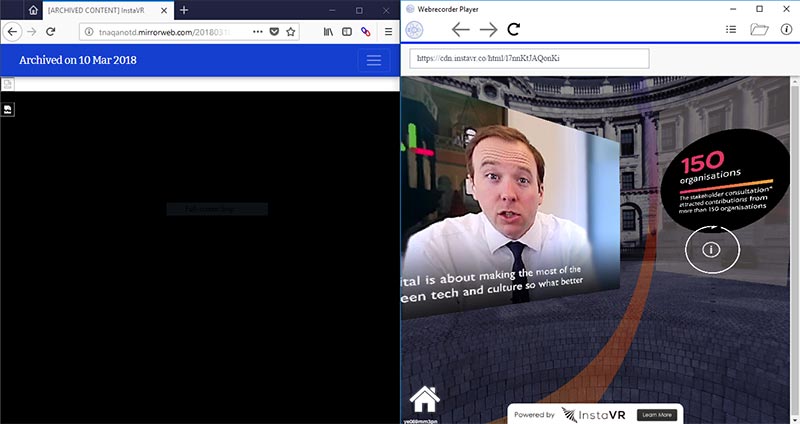
Capturing complex web pages with the use of Webrecorder in conjunction with PYWB, two open-source tools developed by Rhizome
After a morning of plenary presentations, a break-out session ran in the afternoon. Five multidisciplinary groups were tasked with generating ideas for research projects which would demonstrate the value and significance of web archives for research in the arts, humanities and social sciences. They were also asked to identify the most useful actions that web archives could take to open up their collections to researchers of all kinds.
Areas for future research suggested by the groups included: the history of online advertising; the analysis of viruses and malware in web archives; histories of organisational change as it plays out on the web; the study of web art and digital creative literature; the exploration of online redaction and emendation; and an investigation of digital communication by government. The richness of the archived web as a primary source is well illustrated by the range and diversity of the topics identified – and the discussions could have continued for much longer than the time available.
There was less variation when it came to thinking about what might encourage researchers to make greater use of web archives, whatever their interests. Among the key themes that emerged were the importance of easy access, including the ability to download data; the requirement to enhance discoverability, which was linked to the ability of researchers to cite and share data from web archives; the need for ongoing advocacy, communication and education; and the desire for greater clarity about copyright issues.
The workshop has laid vital groundwork for the planning of future research activities, and we hope will have seeded some important collaborations and partnerships.
This research is part of a series of digital experimentation workshops organised by the Research team at The National Archives in collaboration with different universities.
This blog was co-authored by Dr Eirini Goudarouli, Digital and Technology Research Lead at The National Archives, and Professor Jane Winters, Professor of Digital Humanities at the School of Advanced Study, University of London.
[…] Facebook […]