Since 2014, The National Archives has been opening up our collection of handwritten First World War diaries, which document the story of the British Army and its units on the Western Front. Using the crowdsourcing platform Operation War Diary, ‘citizen historians’ have tagged 1.5 million digitised pages from the collection. By annotating essential information on each diary page, the project has generated extensive data about military units, including labels for casualties, unit strength, weather, everyday army life, military activities, soldier names and ranks, location names, and dates.
However, since the amount of information captured by the project was so vast, research into how to process and understand this data is required so that we are able to unlock the potential of the diaries to reveal a bigger picture about activity on the Western Front.
This ambition was the subject of two workshops held as part of The National Archives’ digital experimentation workshop series. In collaboration with the giCentre, based at the Department of Computer Science at City, University of London, we explored new ways of accessing and visually representing collections at scale. The data from Operation War Diary provided the content as we explored the challenges that occur at different stages of the data visualisation process.
At both workshops a multidisciplinary group consisting of data visualisation experts, digital humanists, computer scientists, archivists and historians came together to share different ideas of how to visually represent the spatio-temporal data derived from Operation War Diary. The aim was to explore different narratives designs, and ultimately create of a browser-based visualisation prototype.
A key area of research for the team was how to manage the level of uncertainty that the tagging process creates. There are many causes of this uncertainty: missing records; misspellings (in original diaries and while digitising) and ambiguities; unreadable parts; lost diaries; and through post-processing of the gathered data. Instead of giving the illusion that the data is complete and clean, the aim of the multidisciplinary group was to design visual representations of military units that are well-suited to factor in uncertainty or noise in the data.
In brief, the group’s approach was to leverage this uncertainty to produce a more ‘organic’ view of a military unit’s movement over time. The group started out by exploring possible geometries to visualise the movement of two selected units, progressing from Belgium to Germany after the war in early 1919. After ruling out several relatively well-established designs, such as points (e.g. animated glyphs), lines (e.g. flow lines with arrowheads), or grid geometries (e.g. OD maps), the group decided on conceptualising a dedicated representation of the selected data that they called GeoBlob.
They define GeoBlob as an abstract representation of spatio-temporal data dedicated to showing uncertain positions and uncertain temporal information of entities that move over time. Instead of showing an entity at a given point in time, GeoBlobs convey an unordered estimation of the possible locations over a temporal window using enclosed shapes, based in spatial and temporal data derived from Operation War Diary data.
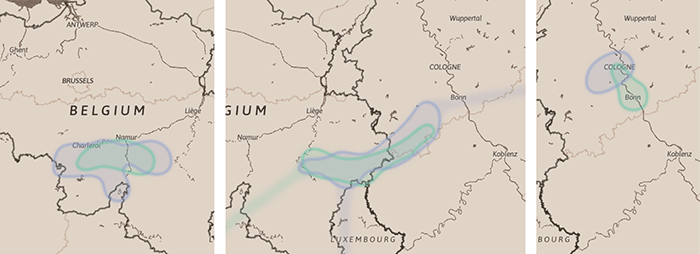
Snapshots of browser-based prototype of two units moving from Belgium to Germany after the war in early 1919 with a temporal window of 10 days.
Based on the findings we have so far, we are exploring funding opportunities to enable us continue creating narrative designs for enriching the current visualisation and including additional information such as text, icons, and media-based annotations of unit events and activities. Our aim is to provide an intriguing and engaging experience for users, whether they are members of the public or researchers from the humanities, digital humanities or data science.
This research forms part of a series of digital experimentation workshops hosted by The National Archives throughout the 2017-8 academic year, in collaboration with different universities. Keep an eye on the blog for more updates on our digital research.
This blog was co-authored by Dr Eirini Goudarouli, Digital Research Lead at The National Archives, and Dr Charles Perin, Lecturer in the Department of Computer Science at City, University of London, and part of the giCentre research group.
Hello
We have a hand written diary from a POW in Berlin – we are looking for it to be sent to the appropriate person for safe keeping and using the fascinating information it holds. It was written by an Alexander Mackie. Sadly we have been unable to locate information about the man himself. Any guidance appreciated.
Hi Pauline,
Thanks very much for your comment.
If you are looking for a good home for a POW’s personal diary, I would suggest getting in touch with the Imperial War Museum (https://www.iwm.org.uk/) or the National Army Museum (https://www.nam.ac.uk/).
Best regards,
Liz.
Just to add to Liz’s comments, I know that IWM (and I suspect other museums such as the National Army Museum) have an involved process for donations that is based on what they already hold as well as what they collect.
With IWM it is best to fill in the online form and and attach a representative scan or image of an entry etc.
You will also need to provide provenance for the item. Please don’t visit your local IWM site – there are five hoping to donate the item there and then because staff are not authorised to accept items.
For more details go to IWM’s page at: https://www.iwm.org.uk/collections/managing/offer-material/how-to-offer
Please don’t let this put you off – but so many people turn up and are then sent away that it is good to know the procedure beforehand.