Our social media archive has been released today, as a collaborative effort between The National Archives and the Internet Memory Foundation, our web archiving supplier.
Capturing content published on blogs has been part of our everyday work for some time. Other social media platforms, such as Twitter and YouTube, are a challenge for traditional web archiving technology. They are highly interactive and instantaneous, and much of the technology that underpins them changes regularly. Social media services are primarily designed with immediate use in mind and, because the content is forever changing and being deleted, it is at a high risk of being lost forever.
Government now uses a wide variety of social media platforms but we have limited this project to Twitter and YouTube as, although archiving them presented unique technical challenges, we were confident that it was feasible. In addition, Twitter and YouTube are heavily used across central government and contain a large amount of information that may not be accessible elsewhere. For comparison, Facebook is far too complex to archive effectively at scale while limiting to government accounts. Flickr is very similar. Now we have developed scalable solutions for Twitter and YouTube we will capture target accounts according to a regular schedule, and ensure this content remains available even after the original accounts have gone.
Taking each platform in turn, below is a summary of the challenges we faced during the project.
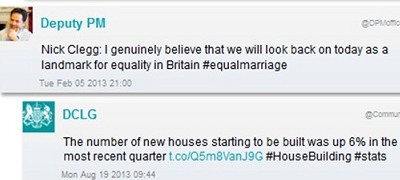
A selection of tweets from the archive
Early on in the social media project, we attempted to capture Twitter using our standard web archiving technology, first through the desktop version and then through the simpler mobile version. Both were extremely limited as they could only capture a maximum of 20 to 200 tweets at a time. We needed a more elegant approach that would provide a better user experience and work at scale in order to meet our collecting requirements.
We decided to archive the content presented through Twitter’s Application Programming Interface (API). The API presents the “raw” data behind each tweet – the tweet’s visible textual content – along with metadata associated with it (date, time, user account, users mentioned and so on). This machine-readable code we then used to provide access. Those familiar with the code will be able to write applications to query it, or integrate it with other data in the future. This also solves the scalability problem as the API provides access to up to 3,200 tweets in one go.
Having a way to download a more comprehensive set of tweets and provide access to them did not mean that we should preserve and give access to them. We can only do this with government-produced content so tweets sent from non-government accounts that form part of a conversation on Twitter haven’t been preserved.
Retweets made by a government account will appear, by default, in the API. However, as retweets are Tweets from different accounts to the account holders we are permitted to capture, we could not justify including them in our archive. We wrote a script which specifically excluded retweets from the archived code.
Our attention then turned to the shortened links. Our analysis has shown that just under 50% of the total tweets we captured had associated short links, created by using a service like http://t.co. Shortened links enable the user to link to a webpage while reducing the number of characters they have to use to do so (space is precious as tweets are restricted to 140 characters). The challenge here was to allow the user to see the intended destination for a shortened link without archiving content from websites that are not within scope for our web archiving activity.
We wrote an application that expands the shortlinks and determines which final URLs are from government websites and which aren’t. For those that do go to government websites and are captured, we provide normal access to the archived webpage, for example:
http://webarchive.nationalarchives.gov.uk/20130918000000/http://t.co/RO2t7QglgZ goes to http://webarchive.nationalarchives.gov.uk/ 20130918000000/https://www.gov.uk/government/speeches/traffic-signs-2013-the-new-framework.
For those that do not go to a government website, we normally display a message like this, and that message provides the expanded link for users to check on the live website, should they wish.
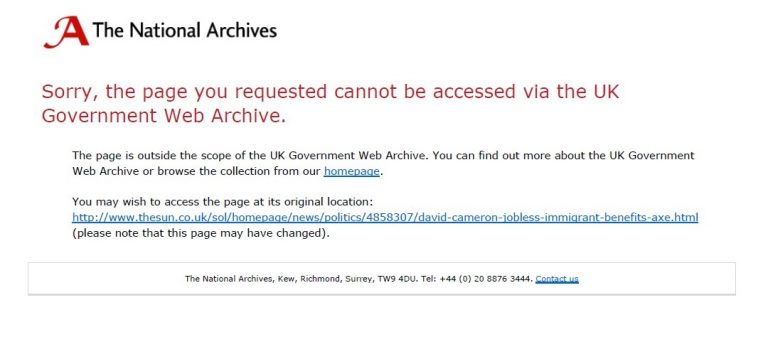
Message displayed for links that do not go to a UK government website
Having archived the tweet data and their associated links, we then integrated the data into a user interface you can see.
Today we’re publishing the results of the tweets captured as part of the pilot stage of the project. They provide a fascinating insight into government’s use of social media and recent cultural and political events.
This archive will continue to grow. We’re aiming to capture every tweet that’s within our remit and we’ll improve access and integration with the wider UK Government Web Archive collection. Please feel free to explore this for yourself. [ref] 1. We don’t have a search function for Twitter content yet, but there is a workaround. While on the page www.nationalarchives.gov.uk/webarchive/twitter.htm, you can download all the .json and .xml into a folder and search within them by specifying indexing options in Microsoft Windows or using an application like Notepad++ for Windows or EasyFind for Mac. [/ref]
Video archive

Tony Blair and Arnold Schwarzenegger Climate Change Press Conference, 2007
YouTube posed different challenges. We’ve been able to capture video content for some time, so the main challenge was to modify the technology the web archive is hosted on to allow for streaming video, integrate the metadata alongside it, and develop a new infrastructure that allows very large files to be played back in full.
The videos, along with their metadata (titles, dates, description, tags, and so on), were gathered from the YouTube API and then inserted into the pages you can now see. On these pages, we use a media player to stream the video and also a download link.
Each future capture of a particular YouTube channel will add new content to the existing system, so ease of navigation was of primary importance. Users can browse by year of video creation, tag, or by keyword searching.
You can see the very early days of the present coalition, in this video, and there’s also Tony Blair’s press conference with Arnold Schwarzenegger, from 2007. You can view the full archive here.
This project and its outcomes illustrate one of the most significant questions in web archiving: how can we keep up with the ever-changing web? The emergence of Twitter and YouTube illustrates a significant change in the use, and users, of the web: from static, detailed information on html pages to fluid, instant media, needing little technical training to publish the content, while giving users the tools to reach their audience quickly, anywhere and at any time. Capturing the record where it is published on a variety of platforms, preserving it and keeping it accessible is a challenge – where should our efforts be focussed in the next few years?