Any researcher who has used online newspaper archives, repositories of digitised books or even resources like The National Archives’ Cabinet Papers Online will recognise the revolution created by optical character recognition (OCR) technology. It is this technology which enables us to search not just the title, or date, but actually the words written inside a book, newspaper or archival document. OCR has transformed the way many scholars conduct their research and opened up huge areas of scholarly endeavour which were previously unimaginable. For those of us who work on archival collections this revolution has always come with a caveat – OCR does not work on handwritten documents. It is for this reason that we are so excited by the new platform called Transkribus, developed by the EU funded READ Project. This offers, for the first time, the potential to use computers to ‘read’ handwritten documents.

PROB 11/2105/1 – Can you read this will from 1849?
The technology behind Transkribus is still very new and The National Archives has been running a pilot project to test out the feasibility of using this type of handwritten text recognition (HTR) software. For this project we decided to focus on our collection of PROB 11 wills. The reasons behind this were largely driven by the technology; these volumes contain clerks’ copies of wills, so the handwriting style is very uniform, and they are legal documents and therefore have structured language patterns. They are also an extraordinary collection of documents containing details of people, places, material goods, social and economic networks, and other factors across time and space. However, as anyone who has used these documents will tell you, they are not the easiest things to read – for this reason they appeared to offer an excellent test for this new technology.
The Transkribus software works by training a model on accurate transcriptions of documents. Researchers upload images of some of their documents and then match up a correct transcription with the text in the images. This allows the model to learn the style of hand and language patterns. This training data is referred to as ‘ground truth’. The trained model can then be used to automatically transcribe similar types of documents in terms of language, handwriting, and so on. As you would expect, the more training data you feed in, the better the results you can achieve from your model.

Segmentation – adding text regions and base lines
The first stage of the HTR process is to upload images of your documents onto the platform, and then carry out a task called segmentation. This entails defining the ‘text regions’ and lines of text. Basically this tells the software where to look for text. This process is largely automated, but it is sometime necessary to check and amend the results. Once this is complete you can either upload your training data, or once you have a model, run the HTR software to produce an automatic transcription.
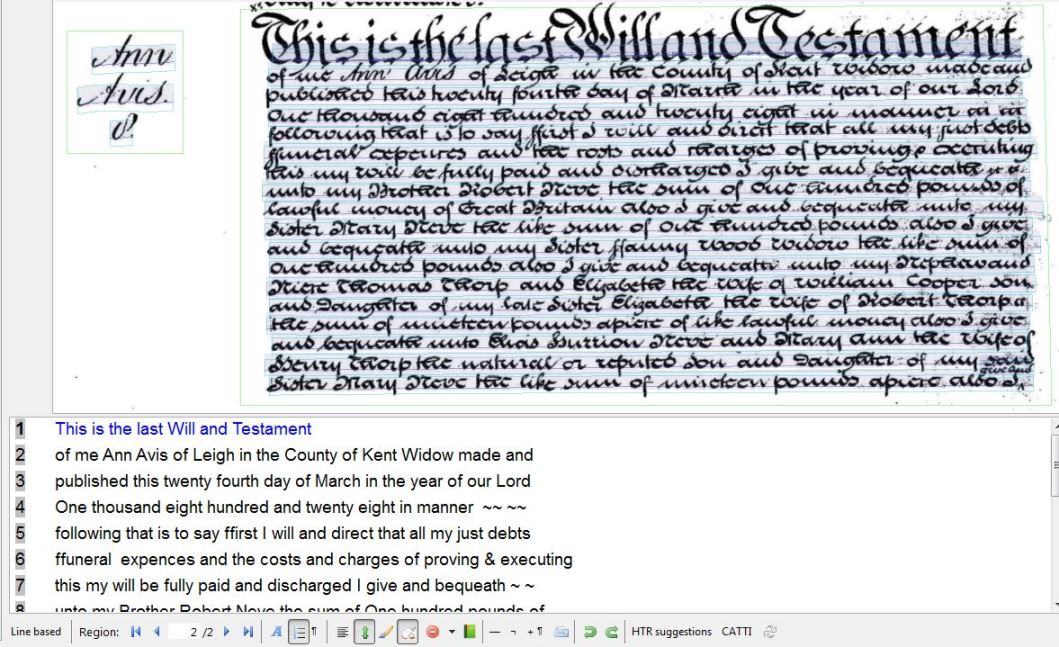
Adding “ground truth” transcriptions
We began experimenting with the software a little while ago, and had some good results from a model trained on a relatively small set of training data (roughly 15,000 words). The accuracy of OCR and HTR transcriptions is measured in terms of Word Error Rate (WER) and Character Error Rate (CER). Our first model achieved a WER of 39% and a CER of 21%. Encouraged by these figures, we produced some more training data and developed a new model based upon roughly 37,000 words. Happily this showed a major step forward in accuracy, with a WER of 28% and a CER of 14%.

Comparing the correct text with the automatically produced transcription
This represented a good result – but clearly, with over a quarter of all words being incorrect, there was still some way to go. The trouble was that transcribing large quantities of these wills is a difficult and time consuming operation. Thus we turned to our community of online volunteers to help develop a larger set of training data. Thanks to the amazing work of a number of dedicated individuals we have rapidly accumulated an additional 60,000 words of transcriptions which is currently being used to train a new and improved model.
We have high hopes of what this new model will be able to achieve, but I think it is fair to say that it is going to be some time before we can rely solely on computers to read all of these tricky handwritten documents for us. In the meantime, this type of technology offers other potential opportunities, most notably in terms of key word searching, which may have a more profound impact on archival collections in the short term. Put simply, you can use this type of technology to search handwritten documents even when the level of accuracy is not really good enough to produce a transcription. This is because a transcription can only show one possibility for a word on a page, whereas the software itself throws up multiple possibilities for each word. Using clever tools you can search these multiple options with a far greater likelihood of finding the correct word.
This type of technology has the potential to revolutionise the way researchers engage with archival collections and we are really excited to be experimenting with this. This work is, however, only possible because of the commitment and dedication of our volunteers who have done much of the leg work in terms of transcriptions. This serves to highlight once again the interconnections between exciting new digital technologies, and the more traditional archival practices.
We are continuing this work using HTR and will report back soon on the progress with our new model.
Whilst this is an interesting development, it is in my view still a long way from being good enough. I would dispute that the PROB 11 Copy Wills are difficult to read, once you know the format it is fairly easy and it is not a “tricky document”. Of course it still leaves issues, I assume the parish of Leigh is Lee near Eltham. The question is whether the cost outweighs the usefulness, family history researchers want names and addresses to find the information and not everything else.
see my reply to the blog, 6/4/2018
Leigh could also be Leigh near Penshurst/Tonbridge in Kent.
And we are not all family history researchers who are only looking for names and dates. Some of us do want the document in its entirety for the full historical value of the record, and not all researchers are trained in paleography.
I also agree that this is an interesting development but it has a long way to go. The main issue with wills is that the names, both personal and relating to place, are always unique and it is a fact that the indexes to these particular wills at TNA have never been reliable in relation to unusual or unfamiliar names such as those from Wales. This has resulted in great frustration for users of the online indexes through failure to establish whether the will they are seeking is among several possibilities in the index, none of which is a clear ‘match’, but they cannot check without paying for a copy. May I suggest that an audit of the accuracy of the index entries would be an excellent starting point (hugely appreciated by users) before focusing on textual interpretation, because accuracy of the names would immediately assist the countless users who must rely on the indexes for their researches and also assist the preparatory work for computerised reading.
These are fundamentally easy to read and pretty standardised compared to, for example, 16th century star chamber proceedings, but then we have to start somewhere. Would agree with comment about need to get the indexes to prob stuff improved. That would a good crowd sourced project. Then let’s start listing properly some sources such as chancery documents or any other category of as yet largely uncharted material.
Have a look at the Himanis web site and you will see an application of HTR on French royal chancery registers (14&15 chancery) http://www.himanis.org/
I think it is an excellent result when compared to early results from OCR software that was regularly returning 10% accuracy and within 5 years 80%. With the development of machine learning I would not be surprised if HTR software rapidly achieved 60 or 70% accuracy for handwriting styles such as that used in your wills project.
It will certainly take longer to develop accurate HTR for all styles of handwriting but even that is now an achievable target for the future.
Pleased to see TNA take the initiative to test the emerging technology on this useful collection. The improvement in WER is encouraging. Better statistics to assess the usefulness would be the accuracy on proper name/capital letter words. Please post those if available.
[…] See TNA’s blog post on their website here: http://blog.nationalarchives.gov.uk/blog/machines-reading-the-archive-handwritten-text-recognition-s… […]
I find admirable this new development. I worry it has to do with patterns , however, which might lead to misreading and misinteroretation. All in all, I find that some measure of light is better than none. Congratulations, amazing tool.
I’m quite excited to see ongoing advances with OCR tech. Are there any efforts being done to run facial recognition models to identify people buried in the collection?
As one who is currently transcribing a number of wills and inventories, as well as other documents, for a history project, I think this is a splendid development and if it opens up access to many other documents in the fullness of time, it is only to be welcomed.
Will medieval Latin be the development to come after this has been cracked?
[…] 02:20:27 Cousin Russ: Machines reading the archive: handwritten text recognition software http://blog.nationalarchives.gov.uk/blog/machines-reading-the-archive-handwritten-text-recognition-s… 02:21:48 Janine Edmée Hakim: Dear Myrtle….speaking of reading handwriting, is the wonderful […]
It seems a very interesting project, and surely in time must open up many possibilities, as others have said. Re David Matthew’s comment, wills provide so much more for family, local and social history researchers than just names of individuals. (And re the parish of Leigh, it is possibly the one near Hildenborough, which incidentally is pronounced ‘Lye’…… an idiosyncrasy I guess the programme will not cope with!) I will look forward to reading about new developments.
[…] Richard Dunley from The National Archives in the UK has recently blogged about his team’s work on a model to process a collection of English Will […]
Whilst I like the idea of opening up the Wills to those who do not have palaeographical training, I do believe there will still need to be an element of historical knowledge to enable a researcher to fully understand the context of the record, and my palaeographical training has been invaluable when researching late medieval records for example. If researchers are genealogists just looking for names and towns and dates, then they are probably not wanting the rest of the information anyway, but there are a great deal of other researchers out there who look for more in a document, and so this will be of great assistance to them, particularly if the technology is then applied to a wider range of historical documents across a wider range of dates, which are not so formulaic in their structure. Following TNA’s progress with interest!
I have been searching for this project for a long time and I think it is feasible. I would like to be a researcher on this area and develop a handwriting recognition for genealogic purposes.
The Transkribus site has a choice of several different charcter sets for OCR. It isn’t clear which is the best one to use for, say, PCC wills from the early 1600s. Can anyone say which is best?
I came across Transkribus before reading this paper. I was translating a mid eighteenth century will. I found the results useful and it was fairly easy to follow and correct the Transkribus raw result.
As you observe the success is very much about the training dictionary. Historical spellings are obviously a challenge which a good training dictionary needs.
Has the TNA considered making available a series of dictionaries aligned to the major sources and time periods so that genealogists (like me) can upload the document images and receive translations. In return I would be very happy to submit possible corrections and clarifications in translations.
Genealogists will have access to other information like parish registers, court records and the like which is useful in checking that one has the correct document.