Last summer I blogged about The National Archives’ collaboration with different universities, part of the research that led to a series of digital experimentation workshops hosted by The National Archives throughout the 2017-18 academic year.
In this blog post, Mark Hedges (from King’s College London) and I will discuss the need for reimagining archival practice in the light of digital and the advantages of the latest computational approaches and techniques.
According to The National Archives’ Digital Strategy, digital technologies are one of the biggest challenges for archives, because of the changing nature of both the record and record-keeping practices. Digital is profoundly shaping what types of records are created and captured, and transforming how records are accessed and used. At the same time, the potential for applying computational methods and tools within archives and, more fundamentally, for integrating ‘computational thinking’ and ‘archival thinking’, has led some researchers to identify computational archival science as a new field of study.
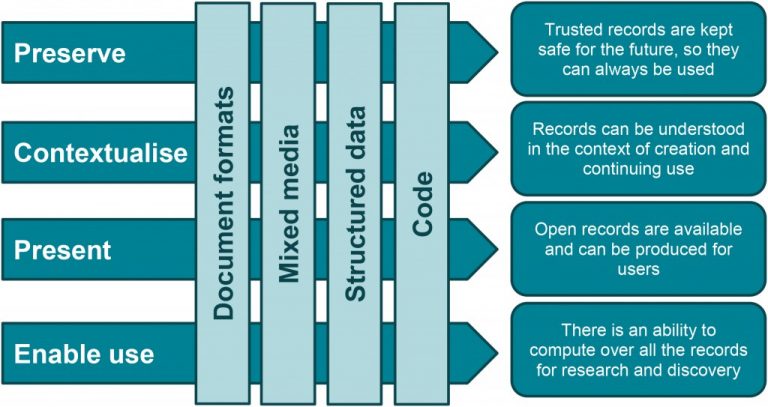
There are four categories for the value the digital archive offers its users
This was the main focus of a workshop organised by The National Archives in collaboration with the Department of Digital Humanities at King’s College London in early September 2018. The workshop was partially supported by the PARTHENOS project, which received funding from the European Union’s Horizon 2020 Research and Innovation programme under the grant agreement 654119.
The workshop, hosted at The National Archives, brought together experts from areas of theoretical and applied computer science with representatives of the archival problem-space to explore new ways of supporting archive professionals in managing and preserving records at scale.
In brief, this multidisciplinary group of experts discussed the application of computational approaches to support archival practice for the creation and preservation of reliable and authentic records and archives, investigating the use of such methods for (partially) automating or assisting archival processes such as appraisal, description, and more.
The discussions were framed by a number of presentations (you can see these here), and mainly explored four areas of research that highlighted
- the work of archivists in creating and preserving records
- the perspective of users in relation to access and interaction with these records
- some theoretical and practical issues around infrastructure
- new needs in the education and training of future (digital) archivists
Within the scope of these four themes, the objectives of the workshop were threefold:
- to identify and evaluate current trends, requirements, potential, and risks in the field, and to examine the consequences and questions that may arise
- to determine possible research agendas and collaborations for the evolution of the field in the coming years
- to establish a community of practice for developing collaborative projects, and liaising with the wider international community in the fiel.
We are planning a follow-up workshop at a venue in London in this academic year to continue the discussion. In the meantime, there is an upcoming workshop on Computational Archival Science at the IEEE Big Data 2018.
This research was part of a series of digital experimentation workshops organised by the Research team at The National Archives in collaboration with different universities for the 2018-19. To find out more about The National Archives’ previous collaborations, you can have a look at my previous blog posts
- with City, University of London, on visualising data from our collections in new ways
- with the University of Cambridge on how to enable complex analysis of large-scale datasets
- with the University of Glasgow on Materialities of Digitisation
- with the School of Advanced Study (SAS), University of London, on Opening up web archives to research and innovation