We have been archiving the online presence of UK central government since 2003. Originally we worked with suppliers to capture traditional websites which we made available for all to browse and search through the UK Government Web Archive.
Since 2014 we have also been collecting some UK Government social media channels. This post (Archiving social media – published in May 2014) describes the original project that we undertook with our former suppliers, the Internet Memory Foundation (IMF), to develop methods of capturing and providing access to Twitter and YouTube channels.
The project was partially successful. We developed a method of capturing tweets and YouTube videos and the associated metadata directly from APIs, and providing access to them through a custom interface. We also developed a method of crawling all short links in tweets, so that the links resolved correctly in the archive.
We continued to capture a small number of channels regularly until mid-July 2017, when we started working with a new supplier, MirrorWeb.
MirrorWeb developed a cloud-based method of capturing and providing access. The new method enables us to capture new posts added to channels each day. Previously we were only able to capture each channel in full once or twice a year. We also increased the number of channels we were capturing and took the opportunity to redesign our custom access pages, incorporating feedback from our users. Excitingly, access to images and video content embedded in tweets was made accessible for the first time. The archive was formally re-launched in August 2018, but we always knew it could be even better!
Towards the end of 2018 we launched an improvement project with MirrorWeb. It had three key aims:
- To develop a method of capturing Flickr images. This became urgent as in November 2018 Flickr announced that, as of early 2019, free account holders would be limited to 1,000 images per account and any additional images above that number would be deleted. A survey showed that several UK Government accounts, particularly older accounts which were no longer being updated, were at risk of losing some content.
- To further improve our custom access pages.
- To provide full text search across the social media collection.
The project aims were fulfilled, and the new functionality went live late in 2019.
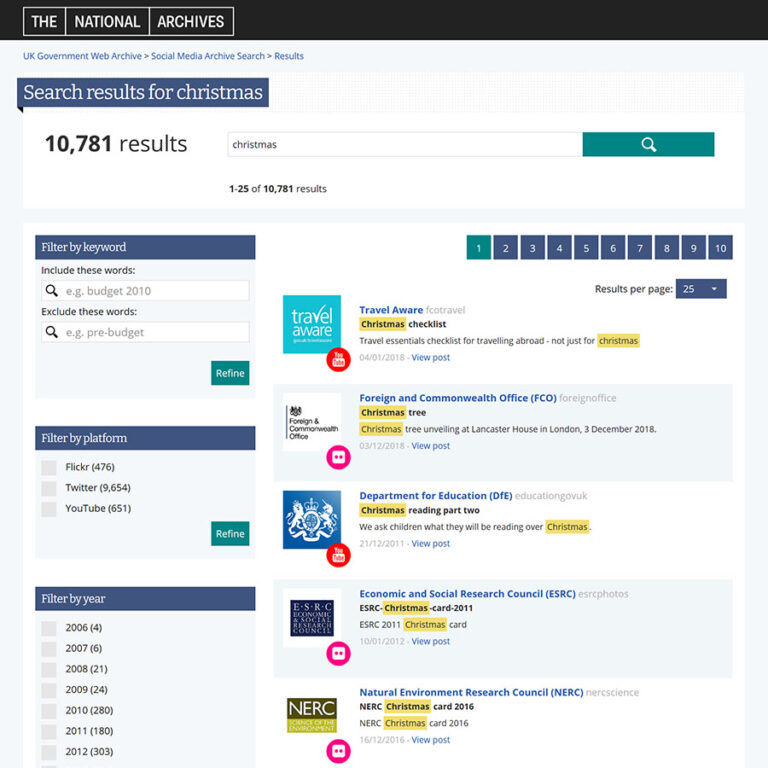
By far the most exciting new development was the implementation of full text search. We undertook some user research earlier in 2018, which revealed that users considered the archive to be interesting but didn’t think it was very useful without search. This emphasized to us how important it was to provide such a service.
The search service was built by MirrorWeb using Elasticsearch, the same technology we use for the full text search facility on the UK Government Web Archive, our collection of archived websites, and is hosted in the cloud.
Each search queries the full text of tweets and the descriptions and titles of YouTube and Flickr content. Users can initially search for keywords or a phrase and are then given the opportunity to filter the results by platform, channel and year of post. They can also choose to only display results which include or exclude specific words.
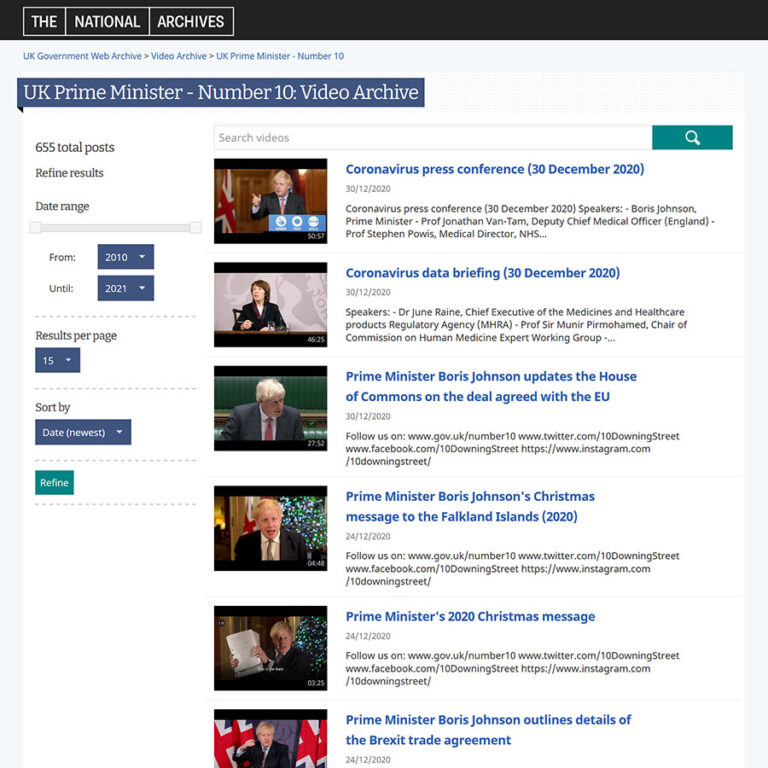
Additionally, we added a search box to the top of each of our custom access pages to enable users to search all data captured from a specific channel. For example, on this page a user can search the titles and descriptions of all the videos we’ve captured from the Prime Minister’s Office YouTube channel.
When we started to investigate capturing social media content over a decade ago, there was a feeling in some quarters that content posted on social media was ephemeral and posts were only being used to point to content on traditional sites. Events of recent years demonstrate that social media is of increasing importance. In some cases, government departments and ministers announce important information on social media some time before they update a traditional website.
We have achieved a great deal already, but we know there is a lot more to do. In future we aspire to add a unified search across our website and social media archives. We are aware that the API capture method does not work for all platforms, so we are actively working to find other methods of capture, particularly for Instagram and Github. We hope to find a way of displaying metadata we capture which is not currently surfaced on the access pages – for example, changes to the channel thumbnail image over time.
We are also aware that there are many gaps in our web archive where we were unable to capture embedded YouTube videos. We hope to develop a method of linking between those gaps and the equivalent videos held in the YouTube archive.
Finally, we plan to do some user research to guide future developments. We are very proud of the UK Government Social Media Archive, and we want to make sure it is used to its full potential.
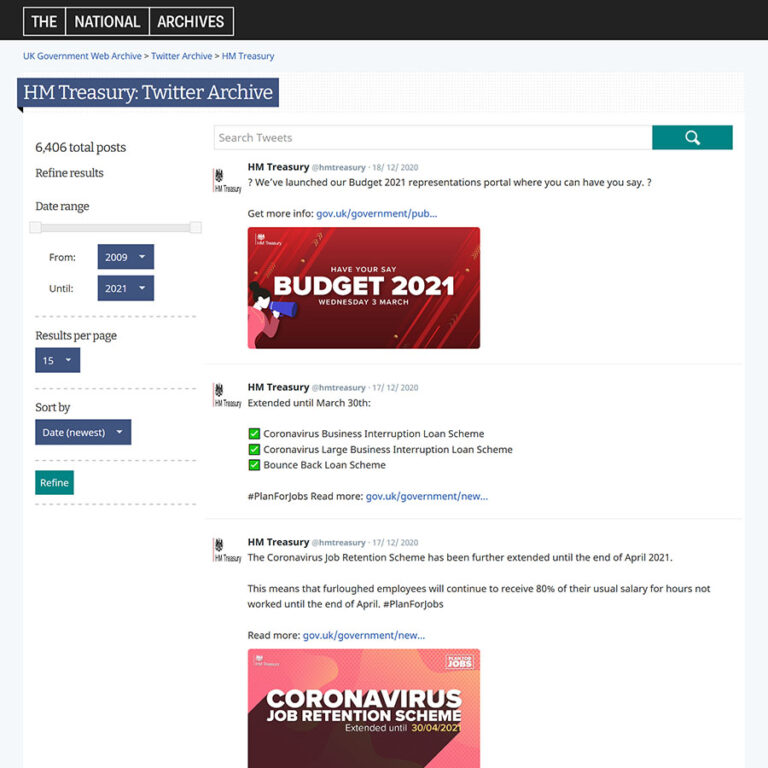
Current access page for archived tweets from the HM Treasury Twitter feed showing embedded media: https://webarchive.nationalarchives.gov.uk/twitter/hmtreasury.
Thank you to Phil Clegg, CTO, MirrorWeb, for his contribution to this post. A version containing more technical detail is available on the International Internet Preservation Consortium (IIPC) blog.