SD – Ahead of Hack on the Record held at The National Archives back in March – the results of which you can see on our Labs website – I discussed with colleagues in the Advice and Records Knowledge department the possibility of pitching interesting and appropriate documents or record series to the developers attending the event. One suggestion regarded the catalogue data for BT 31, a series which contains the files of dissolved companies.
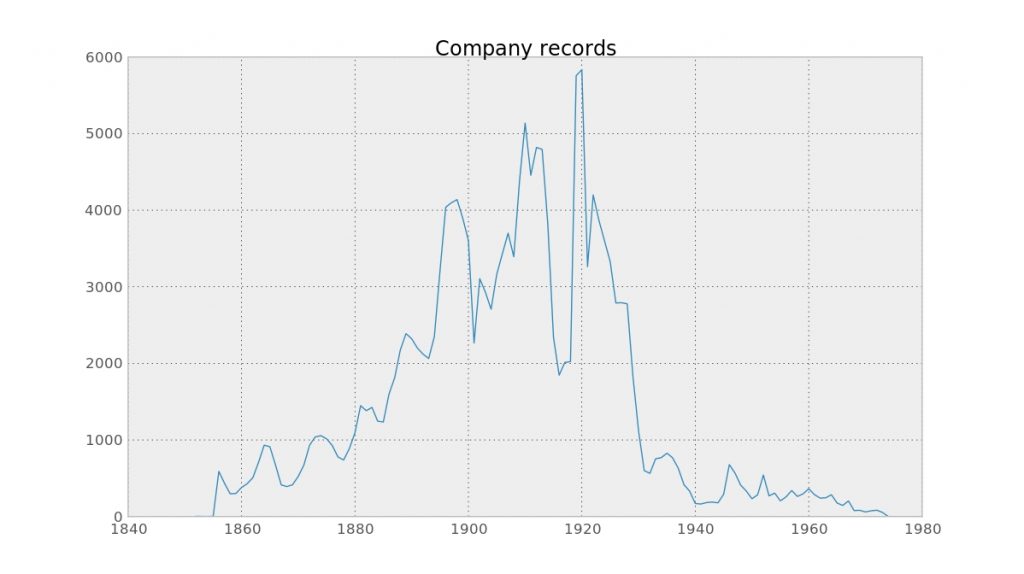
BT 31 relates mostly to the period 1860 to 1930
The above graph is one product of the work done by Matthew Pearce, from The National Archives’ Standards team, who attended the Hack Day as a developer, and felt inclined to work with the BT 31 data. The information – following a recent cataloguing project – is fairly substantive, including companies’ names and years of incorporation, which provided Matthew the opportunity to create various representations of the data. Matthew will now take up the story.
MP – As you can see from the company records chart above, the bulk of the records in BT 31 are from the period 1860-1930, after which the data will be found elsewhere. In total the dataset contains information on over 180,000 companies, with in excess of 600,000 different words used in their names.
That might be small beer on the internet, but it precludes finding interesting trends by eye. The question then is what techniques to use to find unusual events. Clearly we can count up the numbers of times a keyword appears. This, however, captures volume of use alone, not events.
A second method is to look at the behaviour of a keyword over time, working on the premise that noteworthy historical events will cause peaks and troughs in the use of keywords. To give the reader some intuition about what this means: the following chart shows the number of companies with ‘Electric’ in their name divided by the total number of keywords in that year.
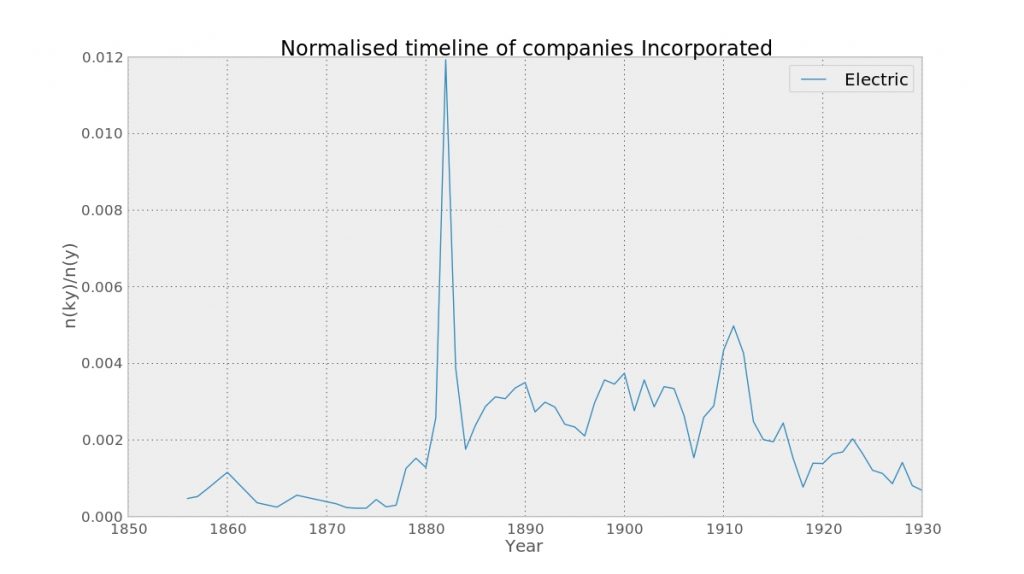
The number of companies with 'electric' in their name spikes in the early 1880s
Thomas Edison invented an improved filament for the electric light bulb in 1880. What’s interesting, looking at the timeline of other developments in the history of the light bulb, is that the companies data reveals which stage was commercially decisive in opening up the market.
Now we can identify other such unusual behaviour through use of information entropy. How unpredictable a keyword is. Essentially, more peaks make for a lower information entropy as it is easier to guess where the mass of keyword use is. A flat graph makes for a high entropy, because the mass is evenly spread out. Using a metric based on this idea, we can generate a list of keywords that might be interesting. Here’s the top ten from one such metric:
0 – Cycle
1 – Picture
2 – Syndicate
3 – Exploration
4 – Coffee
5 – Cinema
6 – Transport
7 – Rubber
8 – Motors
9 – African
Taking ‘Cycle’, we can see that there was something of a boom in the industry between 1890 and 1900.
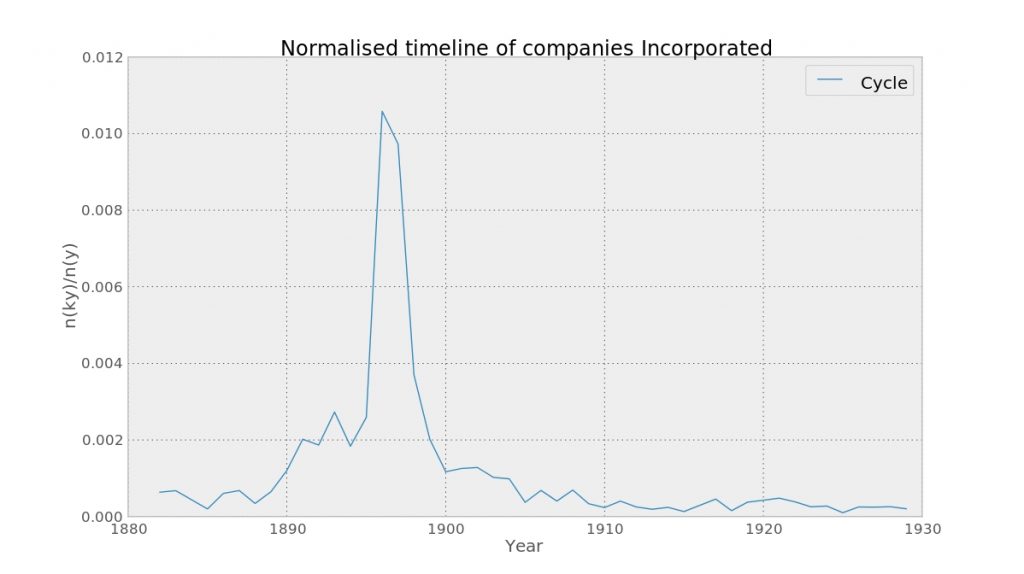
The 'cycle' boom of the mid-1890s
Again innovation was a contributing factor: ‘In 1888, Scotsman John Boyd Dunlop introduced the first practical pneumatic tire, which soon became universal’, along with some other developments you can read about on Wikipedia. Again this is interesting not just for the development of the technology, but for the point at which it became ready for a mass market, with companies stepping up to create and supply a bicycle craze in the 1890s.
One blog post is far too small a space for all the stories waiting in this dataset. ‘Gold’ yields a tale of booms in Australia, America and Africa; ‘picture’: the birth of an entertainment industry; ‘motor’ and ‘rubber’ together track the development of modern transportation and the inustries that supply it. I just hoped to outline here one algorithmic approach to history using the official record as data.
SD – What I find interesting about Matthew’s work on the subject is that it demonstrates one of the main outcomes one hopes for from an event like the Hack Day, showing that new stories and insights into history can be uncovered when technical or mathematical skills are used. Furthermore, by using catalogue data to show the records in a new light he is in a sense mirroring what many of our other researchers do here at The National Archives: using a set of information that was created for one – usually administrative – reason for a different research purpose.
Also, as Matthew suggests, one blog post is not enough space to extrapolate on his work, so we hope to update you on developments in the future. Furthermore, we are interested in any readers who may have conducted similar research. If so, please tell us of your experiences below.
My subject is the history of road passenger transport. At present I am Research Co-ordinator in the Roads & Road Transport History Association (R&RTHA).
I have been using files in the BT31 series since the PRO was in Chancery Lane. Applying search words to the indexes like ‘Omnibus’, ‘Road Car’, ‘Motor Service’, ‘Traction’ & ‘Coach’ I have built up a list of TNA File references and I have taken notes from many of these files. This list is still being added to with names that do not include the obvious connection with road passenger transport. At the same time I have found the staff at Companies House very helpful in identifying records that were destroyed and did not reach the BT31 status.
It should also be noted that the smaller collection of files in the BT34 series has important relevance for tracing the liquidation of companies. I have noticed that the indexes to BT31 and BT34 are now linked at TNA, when searching online. This has been a valuable improvement because the BT34 series was previously only accessible by Company Registration Numbers, not Registered Names.
A small group of files has ended up in Classes BT221 and BT226, when special cases were referred to audit or the Official Receiver
Another useful Class of files is in the Chancery Division of the Supreme Court of Judicature. These begin with the letter J, and the J13 series that I have sampled contain some very interesting Affidavits from people involved with proceedings over Winding Up that have run into difficulties requiring Court Orders.
My last point concerns the elusive Unincorporated Business Partnerships in Class BT253 but unless one knows the registration number of the partnership there is little chance of finding the file reference number. There are nearly 1,300 files relating to these partnerships, covering all trades, but I believe a valuable alphabetical index was lost at the time of transfer of Companies House from London (City Road) to Cardiff.