On 6 March I attended the award-winning Digital Preservation Training Programme (DPTP) delivered in partnership with the Digital Preservation Coalition (DPC) and the University of London Computer Centre (ULCC). The trainers Ed Pinsent and Patricia Sleeman, digital archivists at ULCC, were both extremely knowledgeable and helpful.
As a newcomer to the digital preservation field at The National Archives, with a background of record advice/research and more recently IT, I was looking to gain a solid grounding and fundamental understanding of what digital preservation is and how it applies here. I also wanted to know what other institutions are doing to confront this challenge. There were people from various companies, organisations (big and small), backgrounds and professions from librarians to IT developers. This demonstrates how increasingly important digital preservation is becoming to many people.
This is a brief blog post about what I found most useful during the course and will hopefully make clearer to you what digital preservation is and how it all works.
The Digital Preservation Stool is a good start to understanding digital preservation. This focuses on the main three things needed for digital preservation to take place: organisation, technology and resources, with the idea that without one of these three ingredients, digital preservation will collapse or will be inadequate for your institution or organisation.
I found the OAIS model an excellent visualisation of the process of digital preservation from start to finish, although it seems to be much easier said than done. This model was originally devised by NASA so if you think about it, digital preservation really is rocket science. Nonetheless, it provides a good starting point for people to follow and what processes should be in place.
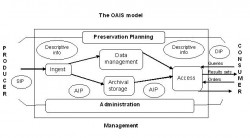
The standard OAIS model
The section of the course called ‘preservation approaches’ was interesting too. This explained the importance of making multiple copies of original material and that these should be placed into a managed storage facility with a robust back up schedule. This section also covered emulation (which keeps digital objects in the same format and recreates the hardware environment in which the object was created) and migration (which transforms the file from its original format to a newer more accessible format to prevent it becoming useless or ‘obsolescent’). The pros and cons were discussed and this remains a hot topic in the digital preservation field. The National Archives’ approach differs to the model above. Find out more about the The National Archives’ approach.
Another thing I found useful, which ties into the OAIS model nicely, was the section about preservation systems. So what is it I hear you say? It is where digital objects are worked on to be processed, preserved and provided to the end users. Preservation systems involve ingest (taking in the digital record/object) and what happens at this stage such as virus checking, using DROID and other tools to identify formats and working with metadata.
One of the areas I was looking forward to finding out the most about (mainly because I did not know too much about it) was metadata. I learned there are different types of metadata (it’s not just ‘data about data’) such as: technical data (info on resolution, image size, file format, version, size), structural metadata (describes how digital objects are put together such as a structure of files in different folders) and descriptive (info on title, subject, description and covering dates) with each type providing important information about the digital object.
Overall, I found the course excellent and would recommend it to anyone interested in finding out more about digital preservation.
Find further information on the Digital Preservation Training programme.